[meta] Check name variables
m_01_8_check_name
Ross Gayler
2021-05-16
Last updated: 2021-05-27
Checks: 7 0
Knit directory:
fa_sim_cal/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20201104) was run prior to running the code in the R Markdown file.
Setting a seed ensures that any results that rely on randomness, e.g.
subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version a6fb2e3. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the
analysis have been committed to Git prior to generating the results (you can
use wflow_publish or wflow_git_commit). workflowr only
checks the R Markdown file, but you know if there are other scripts or data
files that it depends on. Below is the status of the Git repository when the
results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: .tresorit/
Ignored: _targets/
Ignored: data/VR_20051125.txt.xz
Ignored: data/VR_Snapshot_20081104.txt.xz
Ignored: renv/library/
Ignored: renv/local/
Ignored: renv/staging/
Unstaged changes:
Modified: analysis/index.Rmd
Modified: analysis/m_00_status.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made
to the R Markdown (analysis/m_01_8_check_name.Rmd) and HTML (docs/m_01_8_check_name.html)
files. If you’ve configured a remote Git repository (see
?wflow_git_remote), click on the hyperlinks in the table below to
view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 5c06e88 | Ross Gayler | 2021-05-26 | WIP |
| html | 5c06e88 | Ross Gayler | 2021-05-26 | WIP |
| Rmd | 3ca94f0 | Ross Gayler | 2021-05-24 | WIP |
| html | 3ca94f0 | Ross Gayler | 2021-05-24 | WIP |
| Rmd | a405bec | Ross Gayler | 2021-05-22 | WIP |
| Rmd | b41c57c | Ross Gayler | 2021-05-19 | WIP |
| Rmd | 1499235 | Ross Gayler | 2021-05-16 | WIP |
| Rmd | 411de1e | Ross Gayler | 2021-04-04 | WIP |
| html | 411de1e | Ross Gayler | 2021-04-04 | WIP |
| Rmd | 0bd4a5f | Ross Gayler | 2021-04-03 | WIP |
| html | 0bd4a5f | Ross Gayler | 2021-04-03 | WIP |
# NOTE this notebook can be run manually or automatically by {targets}
# So load the packages required by this notebook here
# rather than relying on _targets.R to load them.
# Set up the project environment, because {workflowr} knits each Rmd file
# in a new R session, and doesn't execute the project .Rprofile
library(targets) # access data from the targets cache
library(tictoc) # capture execution time
library(here) # construct file paths relative to project roothere() starts at /home/ross/RG/projects/academic/entity_resolution/fa_sim_cal_TOP/fa_sim_callibrary(fs) # file system operations
library(dplyr) # data wrangling
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionlibrary(gt) # table formatting
library(stringr) # string matching
library(vroom) # fast reading of delimited text files
library(lubridate) # date parsing
Attaching package: 'lubridate'The following objects are masked from 'package:base':
date, intersect, setdiff, unionlibrary(forcats) # manipulation of factors
library(ggplot2) # graphics
library(skimr) # compact summary of each variable
library(tidyr) # data tidying
library(glue) # string interpolation
Attaching package: 'glue'The following object is masked from 'package:dplyr':
collapse# start the execution time clock
tictoc::tic("Computation time (excl. render)")
# Get the path to the raw entity data file
# This is a target managed by {targets}
f_entity_raw_tsv <- tar_read(c_raw_entity_data_file)1 Introduction
The aim of this set of meta notebooks is to work out how to read the raw
entity data. and get it sufficiently neatened so that we can construct
standardised names and modelling features without needing any further
neatening. To be clear, the target (c_raw_entity_data) corresponding
to the objective of this set of notebooks is the neatened raw data,
before constructing any modelling features.
This notebook documents the checking of the person name variables for any issues that need fixing.
These variables will be used to construct the main predictors in the compatibility models.
Regardless of whether there are any issues that need to be fixed, the analyses here may inform our use of these variables in later analyses.
Define the name variables.
last_name- Voter last namefirst_name- Voter first namemidl_name- Voter middle namename_sufx_cd- Voter name suffix
vars_name <- c(
"last_name", "first_name", "midl_name", "name_sufx_cd"
)2 Read entity data
Read the raw entity data file using the previously defined functions
raw_entity_data_read(), raw_entity_data_excl_status(),
raw_entity_data_excl_test(), raw_entity_data_drop_novar(),
raw_entity_data_parse_dates(), raw_entity_data_drop_admin(),
and raw_entity_data_drop_demog().
# Show the data file name
fs::path_file(f_entity_raw_tsv)[1] "VR_20051125.txt.xz"d <- raw_entity_data_read(f_entity_raw_tsv) %>%
raw_entity_data_excl_status() %>%
raw_entity_data_excl_test() %>%
raw_entity_data_drop_novar() %>%
raw_entity_data_parse_dates() %>%
raw_entity_data_drop_admin() %>%
raw_entity_data_drop_demog()
dim(d)[1] 4099699 21Take a quick look at the distributions.
d %>%
dplyr::select(all_of(vars_name)) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 4099699 |
| Number of columns | 4 |
| _______________________ | |
| Column type frequency: | |
| character | 4 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| last_name | 0 | 1.00 | 1 | 21 | 0 | 191996 | 0 |
| first_name | 23 | 1.00 | 1 | 19 | 0 | 126589 | 0 |
| midl_name | 252695 | 0.94 | 1 | 20 | 0 | 175742 | 0 |
| name_sufx_cd | 3869063 | 0.06 | 1 | 3 | 0 | 101 | 0 |
last_name100% filledfirst_name~100% filled (23 missing)midl_name94% filledname_sufx_cd6% filled
3 Name length
Look at the distributions of name lengths first, before moving on to analyses more focused on standardisation.
Calculate the lengths of the name variables.
d <- d %>%
dplyr::mutate(
len_last = stringr::str_length(last_name),
len_first = stringr::str_length(first_name),
len_midl = stringr::str_length(midl_name)
)3.1 last_name
last_name- Voter last name
Look at the distributions of name lengths.
summary(d$len_last) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 5.000 6.000 6.345 7.000 21.000 d %>%
dplyr::count(len_last) %>%
dplyr::arrange(len_last) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>") %>%
gt::fmt_number(columns = n, decimals = 0)| len_last | n |
|---|---|
| 1 | 18 |
| 2 | 2,046 |
| 3 | 53,580 |
| 4 | 393,363 |
| 5 | 864,542 |
| 6 | 1,094,952 |
| 7 | 805,773 |
| 8 | 514,347 |
| 9 | 212,379 |
| 10 | 96,777 |
| 11 | 33,039 |
| 12 | 12,034 |
| 13 | 6,844 |
| 14 | 4,239 |
| 15 | 2,679 |
| 16 | 1,632 |
| 17 | 824 |
| 18 | 404 |
| 19 | 152 |
| 20 | 73 |
| 21 | 2 |
d %>%
ggplot() +
geom_histogram(aes(x = len_last), binwidth = 1) +
scale_y_sqrt()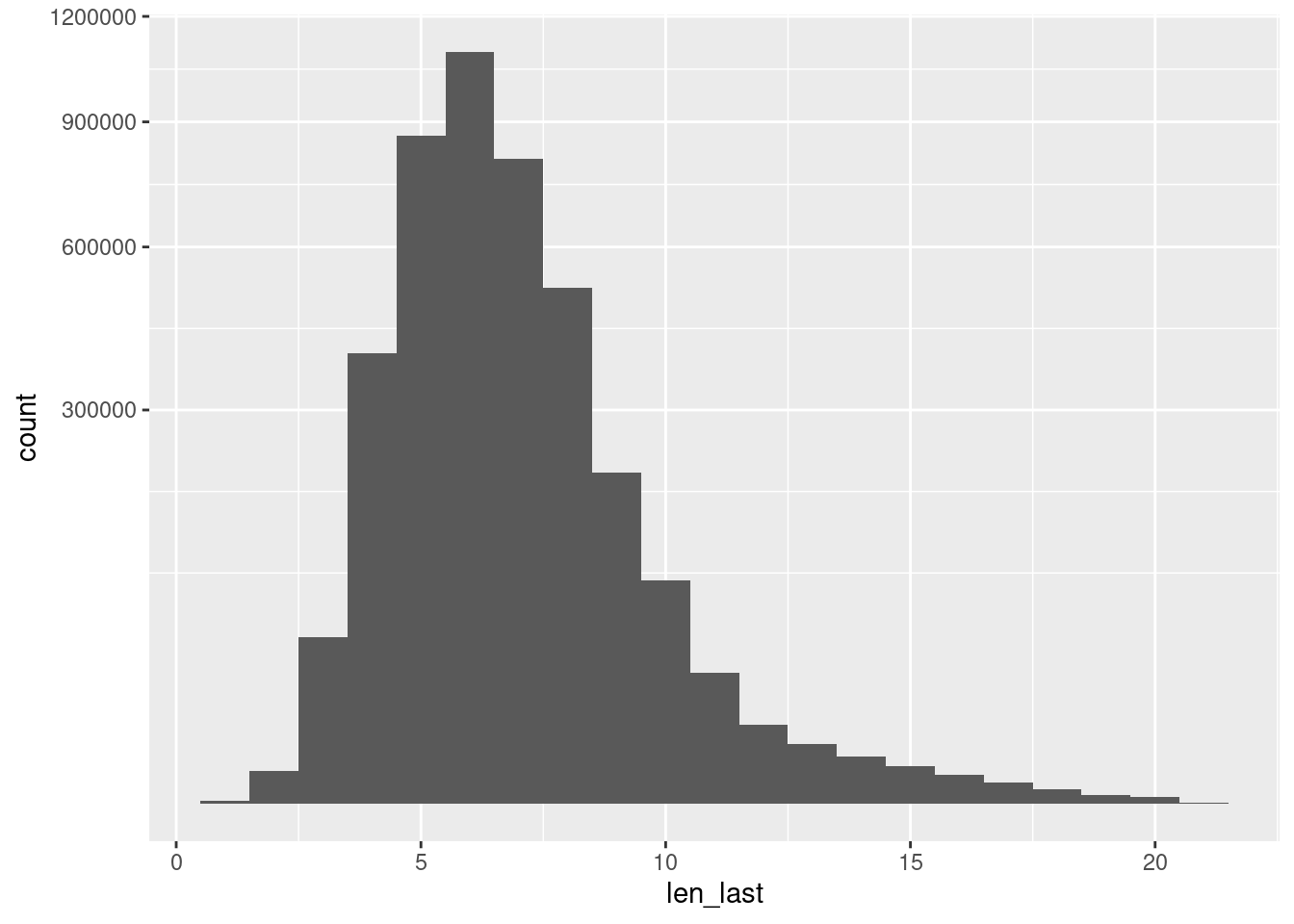
Look at examples of short names.
# length == 1
d %>%
dplyr::filter(len_last == 1) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::arrange(last_name, first_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| A | CHUH | <NA> | <NA> |
| A | THEK | <NA> | <NA> |
| H | MOIH | <NA> | <NA> |
| J | J | <NA> | <NA> |
| K | HOA | HIEP | <NA> |
| K | NGEO | <NA> | <NA> |
| K | NIUH | <NA> | <NA> |
| K | RICHARD | V | <NA> |
| K | SANG | <NA> | <NA> |
| M | COY | FAY | <NA> |
| N | RENEE | VIVIAN | <NA> |
| R | ANDREW | PERNELL | <NA> |
| R | MARY | <NA> | <NA> |
| S | PETER | THOMAS | JR |
| U | RAYMOND | <NA> | <NA> |
| X | MARCUS | <NA> | <NA> |
| X | WILLIE | LARRY | <NA> |
| Y | PRUM | <NA> | <NA> |
- 1-letter last names are very rare
- Most 1-letter last names are probably errors
# length == 2
d %>%
dplyr::filter(len_last == 2) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name, first_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| CO | CONCHITA | <NA> | <NA> |
| DO | KAREN ROSE | ADAMS | <NA> |
| DY | KIAN | LENG | <NA> |
| EU | PANG-CHIEU | <NA> | <NA> |
| JI | STEPHEN | J | <NA> |
| KA | DOM | <NA> | <NA> |
| KC | RABINDRA | <NA> | <NA> |
| KI | WILSON | W | <NA> |
| LA | VINH | D | <NA> |
| MY | SAVATHDY | <NA> | <NA> |
| ON | PHUONG | NGOC | <NA> |
| PE | PATTY | <NA> | <NA> |
| QI | RUI | <NA> | <NA> |
| RU | FENG | YING | <NA> |
| SO | SHIRLEY | MUN YIN | <NA> |
| ST | SING | HARRY NELSON | <NA> |
| TO | HUNG | C | <NA> |
| WA | LONDON | PATRICE | <NA> |
| YI | HEUNG | TAE | <NA> |
| YU | MERCYLYN | MELLA | <NA> |
- Most 2-letter last names are probably valid.
Look at examples of long names.
# length == 21
d %>%
dplyr::filter(len_last == 21) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::arrange(last_name, first_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ALESSANDRETTI-STRAUSS | MARIA | E | <NA> |
| BREWINGTON-SUTHERLAND | LISA | A | <NA> |
- 21-letter last names are hyphenated
# length == 20
d %>%
dplyr::filter(len_last == 20) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name, first_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ARRIAGADA-VALENZUELA | GONZALO | ESTEBAN | <NA> |
| BURLEIGH-KRETZSCHMAR | LINDA | J | <NA> |
| CONSTANTINO-THOMPSON | SANDRA | <NA> | <NA> |
| HARRISON-BASKERVILLE | LADONALL | <NA> | <NA> |
| HOLLINGSWORTH-MILLER | KAREN | <NA> | <NA> |
| HOLLINGSWORTH-PRUITT | TARA | LYNTRELL | <NA> |
| IN DEN BERUEN-KOLMES | D | R | <NA> |
| MORALES-FRANCESCHINI | ERIC | <NA> | <NA> |
| NOOHLANHLA GUGULETHE | ALAMILLA | <NA> | <NA> |
| PIETROMARTIRE-FISHER | ADELE | J | <NA> |
| POLITO-LAUGHINGHOUSE | DEANNA | <NA> | <NA> |
| RODRIGUEZ ECHEVARRIA | ELIZABETH | <NA> | <NA> |
| SCHIAPPACASSE-DEPUTY | ISA | MARIA | <NA> |
| SCHROEDER-KAHLENBECK | REBEKAH | LEIGH | <NA> |
| SLIPENCZUK-MALISZEWS | URSZULA | A | <NA> |
| SOTELO DE LOS SANTOS | MARCOS | ANTONIO | <NA> |
| TASHLEIN-VAN HEUVELN | DARCY | <NA> | <NA> |
| THEODORIDES-GRINESTA | APRIL | ARLETHA | <NA> |
| WHALEY-WOJCIECHOWSKI | KIMBERLY | <NA> | <NA> |
| WOLVERTON-MICHALAKIS | JANET | MARIE | <NA> |
- 20+-letter last names appear to be multi-word and/or hyphenated
3.2 first_name
first_name- Voter first name
Look at the distributions of name lengths.
summary(d$len_first) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 5.000 6.000 5.913 7.000 19.000 23 d %>%
dplyr::count(len_first) %>%
dplyr::arrange(len_first) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>") %>%
gt::fmt_number(columns = n, decimals = 0)| len_first | n |
|---|---|
| 1 | 8,070 |
| 2 | 3,799 |
| 3 | 99,236 |
| 4 | 525,505 |
| 5 | 1,077,727 |
| 6 | 1,018,768 |
| 7 | 884,199 |
| 8 | 295,743 |
| 9 | 135,014 |
| 10 | 19,359 |
| 11 | 29,314 |
| 12 | 1,487 |
| 13 | 880 |
| 14 | 345 |
| 15 | 215 |
| 16 | 9 |
| 17 | 4 |
| 18 | 1 |
| 19 | 1 |
| <NA> | 23 |
d %>%
ggplot() +
geom_histogram(aes(x = len_first), binwidth = 1) +
scale_y_sqrt()Warning: Removed 23 rows containing non-finite values (stat_bin).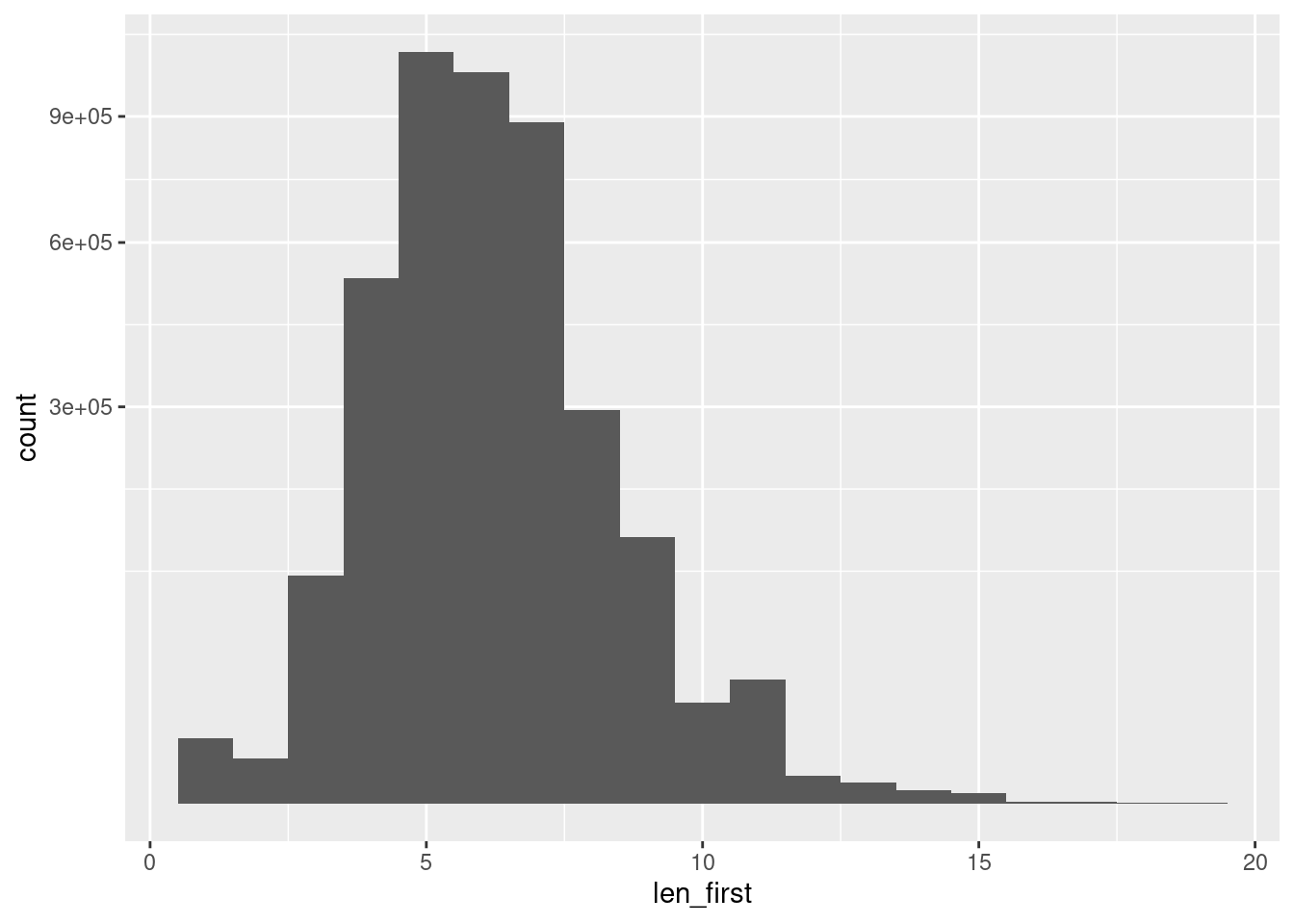
- Possibly more 1-letter first names than I would expect
Look at the missing names.
d %>%
dplyr::filter(is.na(first_name)) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::arrange(last_name, first_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ALEXANDER | <NA> | JASON | <NA> |
| AMEN | <NA> | <NA> | <NA> |
| BULLARD | <NA> | ALEXIS | <NA> |
| BURGESS | <NA> | <NA> | <NA> |
| CHESTER | <NA> | JAMES | <NA> |
| ELSASS | <NA> | <NA> | <NA> |
| FRISBY | <NA> | M | JR |
| FRYE WILLIAM C | <NA> | <NA> | II |
| FUQUA | <NA> | MARY | <NA> |
| FUQUA | <NA> | WILLIAM | <NA> |
| GRAYWOLF | <NA> | <NA> | <NA> |
| JUDITH | <NA> | <NA> | <NA> |
| KAUCHICK | <NA> | PAULINE | <NA> |
| MAGENTA | <NA> | <NA> | <NA> |
| MALIK | <NA> | <NA> | <NA> |
| MCKEEL | <NA> | LESTER | <NA> |
| MOLET | <NA> | MICHAEL | <NA> |
| MORRIS | <NA> | ALEXANDER | <NA> |
| PATTERSON | <NA> | JOHN DEXTER | III |
| PHOENIX | <NA> | <NA> | <NA> |
| SILVERMOON | <NA> | <NA> | <NA> |
| WARREN | <NA> | <NA> | JD |
| ZIMMER | <NA> | CLIFFORD | <NA> |
- Some missing first names look like the middle name is actually the first name, e.g. ? JASON ALEXANDER
- Some missing first names appear to have only a last name, e.g. ? ? AMEN, ? ? GRAYWOLF, ? ? SILVERMOON
- Some missing first names appear to have the entire name in the last name variable, e.g. ? ? FRYE WILLIAM C
Look at examples of short names.
# length == 1
d %>%
dplyr::filter(len_first == 1) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name, first_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ANDERSON | G | P | <NA> |
| BOSTICK | J | RICHARD | SR. |
| EARP | A | JEFF | <NA> |
| ELLIS | N | JEFFREY | <NA> |
| FLYNN | C | PAIGE | JR |
| HINES | C | JON | <NA> |
| JOHNSON | C | ROBERT | III |
| LOGAN | D | ISBELL | <NA> |
| LONG | R | L | <NA> |
| MCBANE | C | RICHARD | JR |
| MELTON | O | MAX | <NA> |
| MITCHELL | J | WESLEY | <NA> |
| MURRAY | C | FRED | <NA> |
| PRINCE | C | M | <NA> |
| SUMMERS | R | J | <NA> |
| SYLVIA | A | M | <NA> |
| TATE | S | LINDSAY | <NA> |
| THOMAS | J | C | <NA> |
| WATSON | R | L | III |
| WHITLEY | R | GAINES | <NA> |
- The 1-letter first names appear to be using an initial as the first name
# length == 2
d %>%
dplyr::filter(len_first == 2) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 50) %>%
dplyr::arrange(first_name, last_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| SHERRILL | AC | <NA> | <NA> |
| FIELDS | AO | <NA> | <NA> |
| TRAN | BA | THI | <NA> |
| NGUYEN | BE | THI | <NA> |
| COLLINS | BO | <NA> | <NA> |
| MATHIS | C. | A. | <NA> |
| HUANG | CE | <NA> | <NA> |
| CIRILLO | CG | <NA> | <NA> |
| BRADLEY | CL | <NA> | <NA> |
| LUONG | CO | HUYEN | <NA> |
| PHUNG | CU | G | <NA> |
| KENNY | DD | THORNTON | <NA> |
| DO | DI | DUC | <NA> |
| MYERS | EB | GORDON | <NA> |
| KOLLITHANATH | FR | PHILIP | <NA> |
| CHAVIS | HL | <NA> | <NA> |
| MOORE | IN | K | <NA> |
| SHEPARD | J. | W. | <NA> |
| MCGILL | JA | KYUNG | <NA> |
| PARAMORE | JI | ANTHONY CARL | <NA> |
| GREESON | JJ | ASHBAUGH | <NA> |
| MANN | JO | P | <NA> |
| LEE | JU | HYUNG | <NA> |
| SPANGLE | KC | <NA> | <NA> |
| DAVIS | KI | FOY | <NA> |
| CHIN | KU | <NA> | <NA> |
| GRANT | KY | AMON | <NA> |
| TON | LO | THAT | <NA> |
| COVINGTON | LV | <NA> | <NA> |
| LOR | ME | <NA> | <NA> |
| MOORE | NE | DEMPSEY | <NA> |
| TLUSTY | NO | ME | <NA> |
| WONG | OI | TUNG | <NA> |
| BRADBURN | ON | PICH | <NA> |
| WILSON | OW | DEMOND | <NA> |
| SIHARAT | OY | <NA> | <NA> |
| BOWLES | PO | SUN | <NA> |
| LY | PY | MUA | <NA> |
| KUYKENDALL | RL | <NA> | <NA> |
| BEASLEY | RO | TALTON | JR |
| MCKINNEY | RT | <NA> | JR |
| NAYLOR | RV | <NA> | <NA> |
| OH | SE | MIN | <NA> |
| TON | UI | THANH | <NA> |
| MOSS | W. | T. | <NA> |
| LOR | WA | LEE | <NA> |
| WONG | WI | HONG | <NA> |
| ZHANG | YI | <NA> | <NA> |
| LO | ZA | TENG | <NA> |
| BLANCHARD | ZO | JONES | <NA> |
2-letter first names appear to be:
- Valid, e.g. JO ANNE COREY, ED ? HODGE
- An initial with punctuation, e.g. A. L LITTLE, D. A. WHITNER
- Multiple initials run together, e.g. GW ? BIVINS, JP ? DENTON
- Part of a multi word name that has bee split across the first and middle name variables, e.g. LA SONDA FOWLER
Look at the long names.
# length >= 16
d %>%
dplyr::filter(len_first >= 16) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 50) %>%
dplyr::arrange(first_name, last_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| FIELDS | ADRIENNE`FELICIA | <NA> | <NA> |
| WINKLER | ELIZABETH PORTIS | G | <NA> |
| MIDDLESWORTH | ELIZABETH-LINDSAY | MCCOY | <NA> |
| NATARAJA | HEGGADADEVANAKOTE | <NA> | <NA> |
| DOUPE | KIMBERLY DANIELLE | WYATT | <NA> |
| SUBRAMANIAM | LAKSHMINARAYANAN | <NA> | <NA> |
| RODRIGUEZ | MARIA DEL CARMAN | <NA> | <NA> |
| ENRIQUEZ | MARIA DEL CARMEN | <NA> | <NA> |
| NUNEZ | MARIANA DE JESUS | N | <NA> |
| ANDERSON | MICHAEL-CHEROKEE | DEMCK | <NA> |
| ODEMS | MICHAEL-CHRISTOPHER | <NA> | <NA> |
| LAPPAS-KOTARA | MICHELLE-ADRIENNE | <NA> | <NA> |
| NAGARAJ | SANTHEBACHAHALLI | S | <NA> |
| PERRY | SHIRLEY ANN-PEPPER | <NA> | <NA> |
| NGUYEN | THI PHUONG KHAUH | <NA> | <NA> |
Long first names appear to be:
- Long non-anglo names, e.g. LAKSHMINARAYANAN
- Multi-word and/or hyphenated, e.g. ELIZABETH-LINDSAY
3.3 midl_name
midl_name- Voter middle name
These names will often be missing or initials only.
Look at the distributions of name lengths.
summary(d$len_midl) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.00 3.00 5.00 4.73 6.00 20.00 252695 d %>%
dplyr::count(len_midl) %>%
dplyr::arrange(len_midl) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>") %>%
gt::fmt_number(columns = n, decimals = 0)| len_midl | n |
|---|---|
| 1 | 826,716 |
| 2 | 10,491 |
| 3 | 289,439 |
| 4 | 440,549 |
| 5 | 651,587 |
| 6 | 705,383 |
| 7 | 508,158 |
| 8 | 227,267 |
| 9 | 114,306 |
| 10 | 30,604 |
| 11 | 20,536 |
| 12 | 9,807 |
| 13 | 5,186 |
| 14 | 3,514 |
| 15 | 3,379 |
| 16 | 50 |
| 17 | 21 |
| 18 | 8 |
| 19 | 2 |
| 20 | 1 |
| <NA> | 252,695 |
d %>%
ggplot() +
geom_histogram(aes(x = len_midl), binwidth = 1) +
scale_y_sqrt()Warning: Removed 252695 rows containing non-finite values (stat_bin).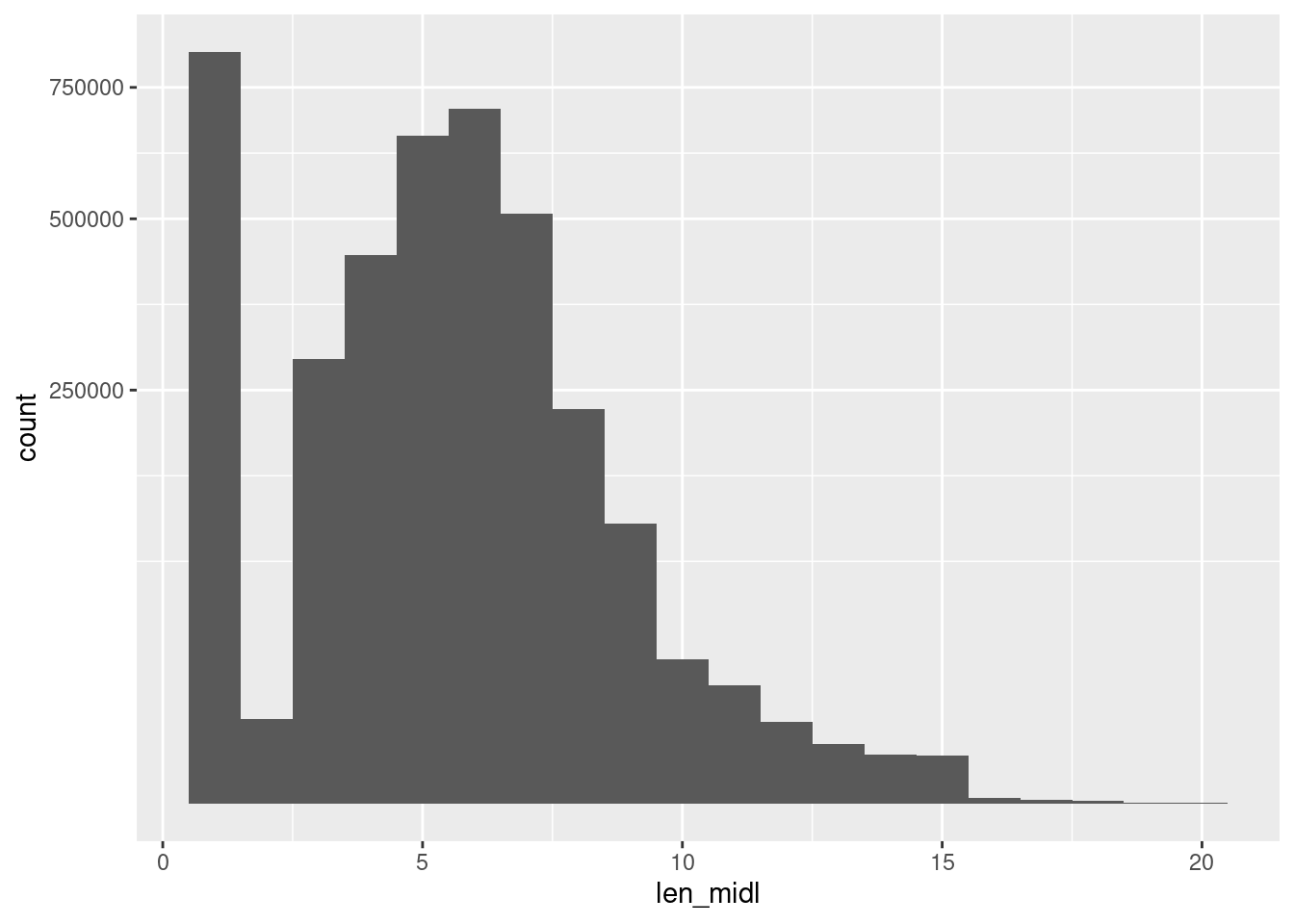
- Many records are missing middle name
- Spike of 1-letter names will be initials
Look at the long names.
# length >= 16
d %>%
dplyr::filter(len_midl >= 16) %>%
dplyr::select(all_of(vars_name)) %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 50) %>%
dplyr::arrange(midl_name, last_name) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| BETSON | JO | ANNE MARY NURTHEN | <NA> |
| BARKER | DENA | ANNETTE FAIRCHILD | <NA> |
| CALL | LUNIA | ANNTONIA MCCRARY | <NA> |
| QUAYE | TINA | ARGENTINUS DEVON | <NA> |
| WOOD | T | BENBURY HAUGHTON | <NA> |
| CUTCHINS | JOSEPH | BENJAMIN FRANKLIN | JR |
| WALL | MELINDA | BERNICE ROBINSON | <NA> |
| DAVIS | SUSAN | BONNER CHRISTOPHER | <NA> |
| PARKER | EDWIN | BROWNRIGG BORDEN | <NA> |
| YOUNGER | ZEE | CAMILLE PREVETTE | <NA> |
| DELLA | MEA | CAROLYN ROBINSON | <NA> |
| NUGENT | JEANIE | CARROLL BURLESON | <NA> |
| WITMER | RUTH | CATHERINE STULLKEN | <NA> |
| WILLIAMS | MAURISA | CECILIA ALEXANDRIA | <NA> |
| GLENN | LINDA | CHERON LEDBETTER | <NA> |
| AVALOS | FAITH | CHRISTINE GIVENS | <NA> |
| GRAY | JAMES | CHRISTOPHER DWAYNE | <NA> |
| MOZINGO | THOMAS | CHRISTOPHER JASON | <NA> |
| BLEVINS | EVA | DOROTHY SHEPHERD | <NA> |
| REYNOLDS | MILDRED | ELIZABETH BARNETT | <NA> |
| HUNTER | CAROL | ELIZABETH BENTON | <NA> |
| LENTZ | ANDREA | ELIZABETH BROWER | <NA> |
| BOYLES | JOYCE | ELIZABETH HOLLAND | <NA> |
| COOPER | NANCY | ELIZABETH HOLLER | <NA> |
| BURGESS | MARY | ELIZABETH NORMAN | <NA> |
| CLARK | AMY | ELIZABETH WILLARD | <NA> |
| CROOKS | KARIM | EMMANUEL SHABAZZ | <NA> |
| MULLINGS | JODI | FINOA LESLEY-ANN | <NA> |
| BOWDEN | CORA | FRANCES THOMPSON | <NA> |
| FARMER | J | H (JAMES HERBERT) | <NA> |
| SMITH | JEWELL | JAHALIA BARRINGER | <NA> |
| SMITH | MYRTLE | JEANETTE CAMPBELL | <NA> |
| WOOD | SMITHIE | JOHNETTE WADDELL | <NA> |
| ARTIST | SYLVIA | JOYCE WIILIAMSON | <NA> |
| MCCORD | MARIAN | KATHLEEN WILLIAM | <NA> |
| EXUM | SHEILA | LANENA WHITEHEAD | <NA> |
| SMITH | ALAN | LAWERENCE KAUFMAN | <NA> |
| SMITH | JOHN | LINWOOD FRANKLIN | <NA> |
| WILDER | VERA | LISA/THARRINGTON | <NA> |
| WHITENER | STEPHANIE | LYNNE WARREN PARKER | <NA> |
| FOTIA | ELAINE | MARIE STINEBAUGH | <NA> |
| HATLEY | EVEIE | MICHELLE RUSSELL | <NA> |
| DUKE | ANGELA | MICHELLE/WILLIAMS | <NA> |
| SHAW | HELEN | PATRICIA ALBRIGHT | <NA> |
| WADDEL | JANICE | PATRICIA MCNEILL | <NA> |
| BISH | FRANCES | PAULINE THOMASON | <NA> |
| ROGERS | RUBYE | REBECCA/SUDDRETH | <NA> |
| CARY | HEIDI | SCHACHTSCHNEIDER | <NA> |
| MILLER | KATRINA | SHEREE BUMGARNER | <NA> |
| BOYD | ALBERT | WILLIAM PRIDGEON | <NA> |
- Long middle names appear to be multiple names and/or hyphenated
- Some long middle names are parenthesised expansions of first and middle names that were given as initials, e.g. A “E (ALONZO EDWARD)” LITTLE
4 Name suffix code
name_sufx_cd- Voter name suffix
This is intended for generation markers, e.g. Junior, Senior.
I am not going to use name suffix in entity resolution because age should be sufficient and is much better quality. I will look at what values turn up in the name suffix because the same values sometimes wrongly occur in the main name variables. Knowing what values occur may help us to remove those values from the main name variables.
d %>% dplyr::select(name_sufx_cd) %>% skimr::skim()| Name | Piped data |
| Number of rows | 4099699 |
| Number of columns | 1 |
| _______________________ | |
| Column type frequency: | |
| character | 1 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| name_sufx_cd | 3869063 | 0.06 | 1 | 3 | 0 | 101 | 0 |
table(d$name_sufx_cd, useNA = "ifany") %>% sort() %>% rev()
<NA> JR III SR II IV JR. SR. I V
3869063 153804 29605 27494 14043 3682 1060 226 218 190
111 MRS 11 VI ` VII MR. MS. J E
67 50 28 27 13 9 7 5 5 4
MR C W SCO S REV R N M JD
3 3 2 2 2 2 2 2 2 2
DR. D ANN 0 (JR X WAL VIR TOB Sr.
2 2 2 2 2 1 1 1 1 1
SMI SAM REE RAY Q PLA P ON OD O
1 1 1 1 1 1 1 1 1 1
MS MOO MMO MD MCQ MAC LOC LLL LL LEW
1 1 1 1 1 1 1 1 1 1
LEE LAR L KIT KEN K JR, JAC ING ILI
1 1 1 1 1 1 1 1 1 1
II. H GUY GLE G FOR FAU F M EY EWA
1 1 1 1 1 1 1 1 1 1
ELS DOR DO DIC CUB CHA B ALB AJR A
1 1 1 1 1 1 1 1 1 1
8TH 5 3RD 39 346 2 1V 15 134 070
1 1 1 1 1 1 1 1 1 1
\\ (II
1 1 d %>%
dplyr::count(name_sufx_cd) %>%
dplyr::arrange(desc(n)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>") %>%
gt::fmt_number(columns = n, decimals = 0)| name_sufx_cd | n |
|---|---|
| <NA> | 3,869,063 |
| JR | 153,804 |
| III | 29,605 |
| SR | 27,494 |
| II | 14,043 |
| IV | 3,682 |
| JR. | 1,060 |
| SR. | 226 |
| I | 218 |
| V | 190 |
| 111 | 67 |
| MRS | 50 |
| 11 | 28 |
| VI | 27 |
| ` | 13 |
| VII | 9 |
| MR. | 7 |
| J | 5 |
| MS. | 5 |
| E | 4 |
| C | 3 |
| MR | 3 |
| (JR | 2 |
| 0 | 2 |
| ANN | 2 |
| D | 2 |
| DR. | 2 |
| JD | 2 |
| M | 2 |
| N | 2 |
| R | 2 |
| REV | 2 |
| S | 2 |
| SCO | 2 |
| W | 2 |
| (II | 1 |
| \ | 1 |
| 070 | 1 |
| 134 | 1 |
| 15 | 1 |
| 1V | 1 |
| 2 | 1 |
| 346 | 1 |
| 39 | 1 |
| 3RD | 1 |
| 5 | 1 |
| 8TH | 1 |
| A | 1 |
| AJR | 1 |
| ALB | 1 |
| B | 1 |
| CHA | 1 |
| CUB | 1 |
| DIC | 1 |
| DO | 1 |
| DOR | 1 |
| ELS | 1 |
| EWA | 1 |
| EY | 1 |
| F M | 1 |
| FAU | 1 |
| FOR | 1 |
| G | 1 |
| GLE | 1 |
| GUY | 1 |
| H | 1 |
| II. | 1 |
| ILI | 1 |
| ING | 1 |
| JAC | 1 |
| JR, | 1 |
| K | 1 |
| KEN | 1 |
| KIT | 1 |
| L | 1 |
| LAR | 1 |
| LEE | 1 |
| LEW | 1 |
| LL | 1 |
| LLL | 1 |
| LOC | 1 |
| MAC | 1 |
| MCQ | 1 |
| MD | 1 |
| MMO | 1 |
| MOO | 1 |
| MS | 1 |
| O | 1 |
| OD | 1 |
| ON | 1 |
| P | 1 |
| PLA | 1 |
| Q | 1 |
| RAY | 1 |
| REE | 1 |
| SAM | 1 |
| SMI | 1 |
| Sr. | 1 |
| TOB | 1 |
| VIR | 1 |
| WAL | 1 |
| X | 1 |
# get a better look at the cleaned suffixes
d %>%
dplyr::mutate(
sufx = name_sufx_cd %>%
stringr::str_to_upper() %>%
stringr::str_remove_all(pattern = "[^A-Z0-9]") %>% # remove non-alphanumeric
dplyr::na_if("")
) %>%
dplyr::count(sufx) %>%
dplyr::filter(n > 1) %>%
dplyr::arrange(desc(n), sufx) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| sufx | n |
|---|---|
| <NA> | 3869077 |
| JR | 154867 |
| III | 29605 |
| SR | 27721 |
| II | 14045 |
| IV | 3682 |
| I | 218 |
| V | 190 |
| 111 | 67 |
| MRS | 50 |
| 11 | 28 |
| VI | 27 |
| MR | 10 |
| VII | 9 |
| MS | 6 |
| J | 5 |
| E | 4 |
| C | 3 |
| 0 | 2 |
| ANN | 2 |
| D | 2 |
| DR | 2 |
| JD | 2 |
| M | 2 |
| N | 2 |
| R | 2 |
| REV | 2 |
| S | 2 |
| SCO | 2 |
| W | 2 |
- Only ~6% of records have a name suffix code
- There are generation suffixes: JR, SR, I, II (11), III (111), IV, V, VI, VII
- There are honorific titles: MRS, MR, MS, DR, REV
- The field lentgh appears to be hard-limited to three characters, e.g. (JR, (II
5 Standardisation
Look at issues that might be addressed by standardisation.
For each type of standardisation issue look at first middle and last names separately, because the issue may manifest differently in each of the name variables.
5.1 Lower-case letters
The alphabetic values are almost entirely upper case. Check for lower case letters.
d %>% dplyr::select(last_name) %>%
dplyr::filter(stringr::str_detect(last_name, "[a-z]"))# A tibble: 3 x 1
last_name
<chr>
1 MacQUEEN
2 MacQUEEN
3 BROWN-McCULLOUGHd %>% dplyr::select(first_name) %>%
dplyr::filter(stringr::str_detect(first_name, "[a-z]"))# A tibble: 11 x 1
first_name
<chr>
1 JoANN
2 LaVERNE
3 JoANNE
4 JoANN
5 SiROBERT
6 McCKINES
7 DeNEAL
8 McHILDIA
9 JoANN
10 LaSONYA
11 JeROME d %>% dplyr::select(midl_name) %>%
dplyr::filter(stringr::str_detect(midl_name, "[a-z]"))# A tibble: 76 x 1
midl_name
<chr>
1 McBRIDE
2 McBRIDE
3 McKINNIE
4 McLAWHORN
5 McKEITHAN
6 McCULLEN
7 MacFRANKLIN
8 McQUEEN
9 McPHAIL
10 McCULLEN
# … with 66 more rows- Lower case letters occur in last, first, and middle names
- Associated with particles where there would optionally be a space, e.g. JoANN, McBride
5.2 Non-alphanumeric
Check for non-alphanumeric characters in names.
5.2.1 Hyphen
Check for hyphens.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "-"))
nrow(x)[1] 20543x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ABU-ELJIBAT | TAREO | <NA> | <NA> |
| ANDERSON-COLLINS | EMMA | T | <NA> |
| ATKINS-GREEN | MUZETTE | CECELIA | <NA> |
| GOODWIN-CARR | KATHY | JAYNE | <NA> |
| HAUSER-PEIFER | CINDY | <NA> | <NA> |
| KEANE-MORGAN | EARTHA | <NA> | <NA> |
| KING- OWEN | GREGORY | SCOTT | <NA> |
| LLOYD-MARSHALL | CHRISTINE | E | <NA> |
| MASON-PALMER | HELEN | LOUISE | <NA> |
| OVER-EVANS | TERRY | LEE | <NA> |
| PATTON-COLE | JAMIE | LYNNE | <NA> |
| PRUDEN-MACHA | PAULA | <NA> | <NA> |
| REA- POTEAT | MARY | BELL | <NA> |
| STONER-TWYFORD | SALLIE | VICTORIA | <NA> |
| UNDERWOOD-TORRES | YVETTE | <NA> | <NA> |
| WALKER-GARY | WANDA | H | <NA> |
| WALKER-HOSKINS | LATONJA | RENEE | <NA> |
| WARE-ROOKSTOOL | MEREDITH | <NA> | <NA> |
| WATSON-MARTIN | FLAPHINE | CRAWFORD | <NA> |
| WHITE-HENSEN | WENDY | EVANS | <NA> |
- ~21k last names with hyphens
- Look like valid hyphenated last names
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "-"))
nrow(x)[1] 3011x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| JACKSON | AL-BEAREE | <NA> | <NA> |
| EL | AL-RAHIM | H | <NA> |
| MILLER | ANNA-MARIA | <NA> | <NA> |
| YATES | ANNE-MARIE | TEMPLETON | <NA> |
| SMITH | EDITH-MARIE | MCCOY | <NA> |
| YELVERTON | GEORGE- KAY | E | <NA> |
| LAO | HUEI-CHEN | <NA> | <NA> |
| WU | I-CHAN | JOHN | <NA> |
| CHEN | JIN-WEN | A | <NA> |
| BARNES | JOHNNIE-MAE | <NA> | <NA> |
| PASSARO | KRISTI-ANNE | TOLO | <NA> |
| WARD | LAURA-JEAN | FORTNER | <NA> |
| PEELER | LES-LEE | ANN | <NA> |
| ROLDAN | LIZ-ANNETTE | <NA> | <NA> |
| BERK | MARGERY-CAROLIN | SIMPKINS | <NA> |
| MEECH | MELISSA-KAYLYN | MAKELY | <NA> |
| MCKENDALL | TE-NISHA | LASHONDA | <NA> |
| DOAN | THANH-TRUC | THUY | <NA> |
| SUN | TZU-KING | <NA> | <NA> |
| EDELEN | WAYLON-JOHN | ANTHONY | <NA> |
- ~3k first names with hyphens
- Look like valid hyphenated first names
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "-"))
nrow(x)[1] 3883x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| HILL | DEIRDRE | ANIS-KING | <NA> |
| LUIHN | DAYNA | ANN-KIERSTIN | <NA> |
| BATTLE | MARY | ANN-SHIPMAN | <NA> |
| HILL | JAMES | CARROLL-JEFFREY | <NA> |
| SORENSEN | VICTORIA | CHERYL-LEIGH | <NA> |
| WESTER | ERIC | GEORGE-DANIEL | <NA> |
| COLLINS | EMILY | JANE-MARIE | <NA> |
| FRAMBACH | NICOLE | JO-VER | <NA> |
| DAVIS | CANDIAS | LA-BIONKA | <NA> |
| CARTER | STEVEN | LA-MARTEZ | <NA> |
| WHEATON | TRICIA | LE-ANN | <NA> |
| HAMPEL | JENIE | LEE-ANN | <NA> |
| LINDSAY | CHRISTOPHER | LEE-JAMES | <NA> |
| EVANS | TOMMI | LYNN-JOSEY | <NA> |
| PRATT | ADA | MAE-DEGRAFFE | <NA> |
| GOULD | JUAQUIN | MYSHIN-SAMI | <NA> |
| KINDLER | REBECCA | NATSUKO-BOWEN | <NA> |
| ROBINSON | SUSAN | NICOLE-BURNETT | <NA> |
| CLARK | TAMIKA | SHAN-TA | <NA> |
| GOWER | CARL | VAN-HOYE | <NA> |
- ~4k middle names with hyphens
- Look like valid hyphenated middle names
5.2.2 Single quote
Check for single quotes.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "'"))
nrow(x)[1] 4920x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| BARDEN-O'FALLON | JANINE | L | <NA> |
| CURE' | TOMILE | TERESA | <NA> |
| D' ANTONIO | AURELIA | EMILIA | <NA> |
| D'ADOLF | RENA | ELIZABETH | <NA> |
| D'ANNUNZIO | TIMOTHY | BRUCE | <NA> |
| D'AOUST | CATHERINE | HUNTOON | <NA> |
| D'ARRUNDA | PETER | JOSE' | <NA> |
| D'ASCOLI | CHARLES | D | <NA> |
| D'AUTRECHY | WILLIAM | JASON | <NA> |
| D'ERCOLE | MICHAEL | E | <NA> |
| D'LACICH | JOHN | ERNEST | <NA> |
| L'HEUREUX | PETER | JOHN | <NA> |
| O' DWYER | BRIAN | <NA> | <NA> |
| O'BRIEN-MOORE | TRACY | MICHELLE | <NA> |
| O'DONNEL | JACQUELINE | E | <NA> |
| O'FAIRE | JOE | WILLIE | JR |
| O'SHAUGHNESSY | ALICE | L | <NA> |
| PLATE' | KEVIN | LOUIS | <NA> |
| R'COM | GULL | M | <NA> |
| TYRE' | ZENA | BRIMMAGE | <NA> |
- ~5k last names with single quotes
- Most look like legitimately quoted last names
- Some look like typos, e.g. LEA’KES, PERRY’KNIGHT
- Some look like they were intended to be diacritics, e.g. GORRE’
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "'"))
nrow(x)[1] 1226x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| BOYD | DE'CARLOS | RASHARD | <NA> |
| AULL | DE'ETTE | SMITH | <NA> |
| HOSKINS | DEL'ANGELO | <NA> | <NA> |
| SAMPSON | DESTINEE' | S | <NA> |
| CHRISTENSON | E'A | LYNN | <NA> |
| FULLER | H'AUNDREA | M | <NA> |
| RCOM | H'TRIM | <NA> | <NA> |
| WILEY | I'AIESHA | SHANTEA | <NA> |
| FLECKENSTEIN | JERE' | DIANE | <NA> |
| SANFORD | JU'CYNTHIA | <NA> | <NA> |
| JACKSON | LA'CHARMIE | NICOLE | <NA> |
| CRUMBLIN-WASHINGTON | LE'RHONDA | DEAN | <NA> |
| ALLEY | LENE' | GEORGETTE | <NA> |
| MOORE | LU'KEASHA | SHANETTA | <NA> |
| DORRANCE | M'LISS | GARY | <NA> |
| GRAHAM | O'JAVELINO | CECILIA | <NA> |
| TAYLOR | RE'DONNA | HAVEN | <NA> |
| SNELL | SHA'DAVA | <NA> | <NA> |
| MUHAMMAD | SHARI'AH | MINA | <NA> |
| HINTON | TE'LISA | NICOLE | <NA> |
- ~1k first names with single quotes
- Most like legitimately quoted first names
- Some look like they were intended to be diacritics, e.g. ANDRE’, RENE’
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "'"))
nrow(x)[1] 3152x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| RUDD | QUIANTA | D'NYNNE | <NA> |
| DUNN | KIMBERLY | D'WANA | <NA> |
| STUKES | MARQUIS | D'WANN | <NA> |
| JAMISON | SHAMEKA | JEVONTE'E | <NA> |
| AUSBORN | MARLON | LA'RAN | <NA> |
| BRIMMAGE | NIKIA | LA'SETTE | <NA> |
| JOHNSON | COURTNEY | LA'SHAWNA | <NA> |
| KNIGHT | ALISON | LENNEE' | <NA> |
| CASHION | ANDREA | M'LEIGH | <NA> |
| BLACK | ANTON | MONTEA' | <NA> |
| DANIELS | JAZLYN | NA'JOY | <NA> |
| STEED | DIANA | O'BERRY | <NA> |
| ROSCHER | KATE | O'CALLAGHAN | <NA> |
| JETER | TRAVIS | O'CASEY | <NA> |
| HICKS | SHANIQUE | O'LET | <NA> |
| LAUNEY | KATHRYN | O'MEALLIE | <NA> |
| TOWNSEND | AMBER | RA'SHONA | <NA> |
| BOYCE | CRYSTAL | RENEE' CHAMBERS | <NA> |
| CATES | SHENERRA | SHA'NEE | <NA> |
| BROWN-JOHNSON | SHAMEKA | TE'ANN | <NA> |
- ~3k middle names with single quotes
- Look like legitimately quoted middle names
- Some look like they were intended to be diacritics, e.g. RENEE’
5.2.3 Double quote
Check for double quotes.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, '"'))
nrow(x)[1] 1x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| LA"BEE | DELACRUZ | <NA> | <NA> |
1 last name with double quotes
- This looks like a typo for a single quote
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, '"'))
nrow(x)[1] 3x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| YOUNCE | GEMES "BO" | MASON | <NA> |
| BALDWIN | HENRYL" | <NA> | <NA> |
| DUNN | MARY ("PETE") | BURNETTE | <NA> |
- 3 first names with double quotes
- 2 are introducing nicknames
- 1 looks like a typo, e.g. HENRYL"
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, '"'))
nrow(x)[1] 1x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| KIRBY | ANNA | "WALANIA" | <NA> |
1 middle name with double quotes
- This this looks like the middle name is the “official” first name and the listed first name is a nickname
5.2.4 Period
Check for periods.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "\\."))
nrow(x)[1] 11x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| BINGHAM JR. | AMES | EDMOND | <NA> |
| DAYE JR. | JAMES | <NA> | JR |
| RUSSELL, JR. | KERMITT | PATRICK | <NA> |
| ST. CLAIR | JACK | LEE | <NA> |
| ST. CYR | CANDICE | NICOLE | <NA> |
| ST. GEORGE | MARTHA | S | <NA> |
| ST. GERMAIN | AMY | <NA> | <NA> |
| ST. JOHN | JESSICA | JO | <NA> |
| ST. LAWRENCE | ELIZABETH | W | <NA> |
| ST.CLAIRE | KEVIN | WAYNE | <NA> |
| ST.JOHN | JOANN | DIMAGGIO | <NA> |
- 11 last names with periods
- Most are the standard contraction of SAINT
- 3 have added the name suffix code JR. to the last name
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "\\."))
nrow(x)[1] 120x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| NORRIS | A.T. | <NA> | <NA> |
| WILLIAMS | C. SHAWN | <NA> | <NA> |
| BROTHERTON | DEBORAH W. | JOST | <NA> |
| CALLICUTT | J.C. | <NA> | JR |
| ELLERBE | J.P. | <NA> | <NA> |
| RENDLEMAN | J.T. | <NA> | <NA> |
| OLIVER | KIMBERLY C. | SHEARIN | <NA> |
| LATTA | L.B. | <NA> | JR |
| WILLIAMSON | L.C. | <NA> | <NA> |
| HICKS | MARY E. | PALMER | <NA> |
| NULL | P. | JOHN | <NA> |
| GARSKA | P.J. | JAN DE BEWR | <NA> |
| MOORE | R. | C. | <NA> |
| PARHAM | S. | MALONE | <NA> |
| HARKINS | SHARON F. | ATKINSON | <NA> |
| TANNER | T. | BRADLEY | <NA> |
| WILSON | URSULA D. | PENN | <NA> |
| PANZER | VICKIE S. | LEWIS | <NA> |
| TURNAGE | VICKIE C. | JENKINS | <NA> |
| CHANDLER | W.(WALTER) | CARL | <NA> |
- 120 first names with periods
- These look like punctuated initials
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "\\."))
nrow(x)[1] 2233x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| HICKS | VIRGINIA | (GINNY) E. | <NA> |
| CRANFORD | JUNE | (MISH) E. | <NA> |
| IEVOLI | ELLEN | B.M. | <NA> |
| EATON | ELLEN | DORITA C. | <NA> |
| COTHREN | MARY | ELLEN L. | <NA> |
| WORLEY | CLAUDIA | H. PRESSLEY | <NA> |
| KING | ENA | ISCHELLE R. | <NA> |
| CAHOON | JULIA | J. | <NA> |
| ELLER | LOU | J. KIMSEY | <NA> |
| LOYD | RUBY | JUANITA B. | <NA> |
| COPELAND | MARY | L. JOHNSON | <NA> |
| HENDERSON | JANE | L. ROBERSON | <NA> |
| SMITH | AUDREY | M. BURCH | <NA> |
| ROBERSON | LILLIE | M.C. | <NA> |
| LITTLE | HILTON | MRS. | <NA> |
| DAVIS | ODELIA | P. | <NA> |
| TEESATESKEE | TINA | S.JAMES | <NA> |
| WATKINS | WILLIAM | S.P | <NA> |
| MOTHERSHED | JAMES | T JR. | <NA> |
| JOHNSON | DOUGLAS | X. | <NA> |
- ~2k middle names with periods
- These look like punctuated initials
5.2.5 Comma
Check for commas.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, ","))
nrow(x)[1] 2x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| FILLINGHAM, II | ROBERT | E | <NA> |
| RUSSELL, JR. | KERMITT | PATRICK | <NA> |
- 2 last names with commas
- Punctuation for suffix field values added to last name
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, ","))
nrow(x)[1] 4x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| PHILLIPS | FRANK, | <NA> | JR |
| HICKS | MARION, | <NA> | SR |
| CANIPE | NOAH, | <NA> | JR |
| MCADAMS | WILL,JR | <NA> | <NA> |
- 4 first names with commas
- Arbitrary added punctuation
- Punctuation for suffix field value added to first name
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, ","))
nrow(x)[1] 12x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| FAUCETTE | JESSE | EDWARD, J | <NA> |
| BRASWELL | ROBERT | ELLIS, J | <NA> |
| MARTIN | LLOYD | FRANKLIN, S | <NA> |
| GAY | ROBERT | HENRY, III. | <NA> |
| FERGUSON | STANTON | HYDE, J | <NA> |
| CLARK | COLEMAN | JACKSON, I | <NA> |
| BARNES | RUSSELL | JOSEPH, J | <NA> |
| PIERCE | RUTH | P, | <NA> |
| COVINGTON | EDNA(MRS | PERRY, JR) | <NA> |
| SCARBOROUGH | JOHN | R, | <NA> |
| SHEARIN | ANDREW | THOMAS, S | <NA> |
| WILLIAMS | ERVIN | W., SR., | <NA> |
- 12 middle names with periods
- List separator
- Punctuation to squeeze in extra field
5.2.6 Space
Check for whitespace characters.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "\\s"))
nrow(x)[1] 7380x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ABDEL RAHMAN | AHMAD | <NA> | <NA> |
| DE LA HOZ | JAMIE | LEE | <NA> |
| HARGRAVES JR | JAMES | CALVIN | <NA> |
| HUNT- BREUER | JEAN | <NA> | <NA> |
| LEONALL - MERRITT | TINA | K | <NA> |
| MARTIN HALL | KIRA | JOAN | <NA> |
| MOORE- BIG EAGLE | RAMONA | R | <NA> |
| NIEC- GRAY | NANCY | MACQUARRIC | <NA> |
| PEREZ VASQUEZ | FELIPE | <NA> | <NA> |
| RAMOS AGOSTINI | GERARDO | ENRIQUE | <NA> |
| ROEDE BARBEE | ELIZABETH | CATE | <NA> |
| SNOW WICKER | CHERYL | LUCILLE | <NA> |
| TEN KATE | LINDA | HAWN | <NA> |
| VAN DEN BROEKE | RAYMOND | BERNARD | <NA> |
| VAN DYKE | RUTH | WILKERSON | <NA> |
| VAN LIEW | CATHERINE | E | <NA> |
| VAN MEERTEN | JAMES | A | <NA> |
| VAN RAVESTEYN | JAN | AUGUST | <NA> |
| VAN TASSELL | JACK | S | <NA> |
| VON OLHAUSEN | LINDA | LEONORA BOWERS | <NA> |
- ~7k last names with whitespace characters
- Most look like substitutions for hyphen or quote
- Some are word separators
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "\\s"))
nrow(x)[1] 12492x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| FOX | DIANNE CARO | KELLY | <NA> |
| MURCHISON | GAIL ANN | MCGARY | <NA> |
| PURCELL | GRACE VIRGINI | TORRENCE | <NA> |
| BENNETT | HELEN ANN | OWENS | <NA> |
| GODLEY | JEANEL LYNN | FILIPKOWSKI | <NA> |
| YUN | JUNG HAN | PETER | <NA> |
| MIKKELSEN | KIM RAE | KRUSIK | <NA> |
| MCDANIEL | LA NORRIS | ANDREW | <NA> |
| JONES | LA SHAN | TRINI | <NA> |
| DOUGLAS | LA SHANDA | <NA> | <NA> |
| CHAN | MAN YEE | <NA> | <NA> |
| FRENCH | MARIE CARMEL | Y | <NA> |
| BAKER | MARY DELL | P | <NA> |
| HARTNETT | MARY MITCHELL | HAYES | <NA> |
| HANCOCK | NANNIE FAE | MCNAIR | <NA> |
| HILL | PANDORA RENEE | CHAMBERS | <NA> |
| HAZEL | ST ANTHONY | ROBERT | JR |
| ROMEI | WILMA LOUISE | BURROWS | <NA> |
| MACK | YOLANDA D | S | <NA> |
| NORTON | ZA HARY | EMMANUEL | <NA> |
- ~12k first names with whitespace characters
- Most look like word separators
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "\\s"))
nrow(x)[1] 47314x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| PLUM | BELINDA | ANN INGRAM | <NA> |
| CARLSON | SHIRLEY | ANNE FIELDS | <NA> |
| ADAMS | SANDRA | CARMILLE BAILEY | <NA> |
| SHOFFNER | LYTONYA | DENEEN HARRISON | <NA> |
| ROPER | THOMAS | E DR | <NA> |
| SIBLEY | BRENDA | F ALBRIGHT | <NA> |
| MAIN | JOSHUA | GEORGE ALAN | <NA> |
| JAGER | MARGARET | JANE WYATT | <NA> |
| CARNEY | BETTY | JEAN WILKINS | <NA> |
| WATSON | IRMA | KAREN L | <NA> |
| JONES | ASHLEY | KNECOLE MAMIE | <NA> |
| SIPE | JANET | LEE LAIL | <NA> |
| DYE | WENDY | LEE SCHOENDUBE | <NA> |
| SPAIN | LIZZIE | LOIS BROOKS | <NA> |
| CULLEN | DOROTHY | M RICHMAN | <NA> |
| ODOM | PATRICIA | MARIE BEVAN | <NA> |
| LADD | LENA | O LUNSFORD | <NA> |
| KRUEMMEL | JANET | ROSS STEELE | <NA> |
| SCHUETZ | IRIS | RUTH DEGENHARDT | <NA> |
| PARSONS | INA | RUTH MULLIS | <NA> |
- ~47k middle names with whitespace characters
- Most look like word separators
5.2.7 Other non-alphanumeric
Check for other non-alphanumeric characters.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "[^ a-zA-Z0-9\\.,'\"-]"))
nrow(x)[1] 30x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| BRINKLEY/BAGGS | MICHELLE | LEE | <NA> |
| CARDONA/RAMIREZ | CATHY | SETZER | <NA> |
| COLLINS/SISK | RHONDA | L | <NA> |
| GALINSKY/MALAGUTI | DANA | ANNE | <NA> |
| GOSHEN\ | DIXIE | M | <NA> |
| LIVINGSTON/MILLER | KELLY | SHANTAY | <NA> |
| MARTIN/HUFF | ELLEN | MARIE | <NA> |
| MORRISON` | HAZEL | M | <NA> |
| NICHOLS/BROWN | MARY | SUE | <NA> |
| O*BRIEN | COLIN | JAMES | <NA> |
| O*NEAL | ALLEN | MARVIN | JR |
| O*TOOLE | PETER | TERRENCE | <NA> |
| O~CONNOR-LEWIS | BELINDA | JOY | <NA> |
| REAVIS/LONG | SHAWN | MICHELLE | <NA> |
| RHONEY/PETERS | DONNA | <NA> | <NA> |
| SCHERM%MARTIN | WYATT | <NA> | <NA> |
| SIDI/HIDA | DEBORAH | ANN | <NA> |
| SOLARZ_VOJDANI | JENNIFER | S | <NA> |
| STRTHEIT\ | LOLA | C | <NA> |
| TALBERT/GRAHAM | BRENDA | <NA> | <NA> |
- 30 last names with other non-alphanumeric characters
- Most look like substitutions for hyphen or quote
- Some look like random cruft
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "[^ a-zA-Z0-9\\.,'\"-]"))
nrow(x)[1] 100x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| POTEAT | (KAY) | ANNE CATH | <NA> |
| SINGS | ANTANA` | DEON | <NA> |
| MOTLEY | CHARISSE` | T | <NA> |
| BRUTON | DANIEL (DANNY | C | <NA> |
| COVINGTON | EDNA(MRS | PERRY, JR) | <NA> |
| ARCHIE | JA`TIA | LA'SHAREE | <NA> |
| MCILWAIN | JOE`L | <NA> | <NA> |
| PINNELL | KEVIN_C | <NA> | <NA> |
| HEMPHILL | LA`CHERICA | EVON | <NA> |
| DOLL | LINDA SUSAN/ | GEMBORYS | <NA> |
| BELK | LISA/MELISSA | CHEYENNE | <NA> |
| STROUD-LITTLEJOHN | MARCHE` | ANN | <NA> |
| KERN | O (BUDDY) | R | <NA> |
| BENNETT | RAPHAEL(RAY) | E | JR |
| JENKINS | RO`SHEENA | DANIELLE | <NA> |
| HARRIS | SHA`RON | LATRECE | <NA> |
| HARRIS | SHONDAR`A | LATICIA | <NA> |
| CHANDLER | W.(WALTER) | CARL | <NA> |
| GROSS | WALTER (WALLY | P | <NA> |
| CHANG | YU-JHI(JULIE) | CHEN | <NA> |
- 100 first names with other non-alphanumeric characters
- Some look like substitutions for hyphen or quote
- Some are parenthetical notes
- Some look like random cruft
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "[^ a-zA-Z0-9\\.,'\"-]"))
nrow(x)[1] 1096x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| CANTRELL | ELIZABETH | (BETSY) J | <NA> |
| JONES | ALMA JANE | (CAMPELL) | <NA> |
| JONES | JULIA | (LORI) COPE | <NA> |
| SMITH | ARNOLD | (POLLY) | <NA> |
| ROUSE | ZELLY | A/LEDERFIELD | <NA> |
| WHITTINGTON | LINDA | ANN/KANE | <NA> |
| HYATT | LILLY | BELLE/EZZELL | <NA> |
| DEES | CHALLIS | D (ELEANOR) | <NA> |
| LITTLE | A | E (ALONZO EDWARD) | <NA> |
| HALL | SARAH | ELLEN/SWEET | <NA> |
| MILES | ANNIE | GERENE/MCKOY | <NA> |
| WHITSON | BILLIE | JEAN/STURGIL | <NA> |
| DELONG | MAGGIE | LEE/LOCKLEAR | <NA> |
| HUFFMAN | WANDA | LYNELLE/ANNAS | <NA> |
| JUDGE | SARAH | LYNN(DAVIDSO | <NA> |
| VIAS | LUCILA | PINAV-IN/DED | <NA> |
| BAILEY | WILLIAM | R (BILL) | <NA> |
| GARNER | SHIRLEY | R/STONE | <NA> |
| PLEMMONS | CANDACE | RAE/SPARKS | <NA> |
| STEPHENS | ALICE | RUTH/MCGILL | <NA> |
- ~1k middle names with other non-alphanumeric characters
- Some look like substitutions for hyphen
- Many are parenthetical notes (NMN = no middle name)
5.3 Digits
Check for digits.
5.3.1 Zero
Check for zero
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "0"))
nrow(x)[1] 29x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| BISH0P | AMBER | CLAIRE | <NA> |
| BOLAD0 | PAULA | HUTCHENS | <NA> |
| CAPUT0 | BARBARA | DAVIS | <NA> |
| CONR0Y | WILLIAM | COURTNEY | <NA> |
| EAT0N | VICKIE | TUGGLE | <NA> |
| ESC0BEDO | AUDREY | ANN | <NA> |
| FERGUS0N | TRACY | DAWN | <NA> |
| FERNANDEZ-BRAV0 | GIOVANNI | <NA> | <NA> |
| JOHNS0N | MICHAEL | <NA> | <NA> |
| L0CKLEAR | REEDY | T | <NA> |
| MCD0UGAL | BETTY | JEAN | <NA> |
| OCONN0R | GERALDINE | LOUISE | <NA> |
| PEREZ-NAVARR0 | CAROLE | SHAY | <NA> |
| R0CCO | CHRISTOPHER | <NA> | <NA> |
| REYN0LDS | ADAM | DANIEL | <NA> |
| SCAMARD0 | TERESA | HIGGINS | <NA> |
| SIMPS0N | MARY | ANN | <NA> |
| WINST0N | BRENTON | SCOTT | <NA> |
| WO0DARD | CECILY | STATON | <NA> |
| YATSK0 | JEANETTE | MARIE | <NA> |
- 29 last names with zero
- Substitution for letter O
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "0"))
nrow(x)[1] 33x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| PETTY | ALLIS0N | JEAN | <NA> |
| BROWN | ALONZ0 | <NA> | <NA> |
| AYALA | ANDREA-0 | <NA> | <NA> |
| KNOX | ANTONI0 | F | <NA> |
| TIDDY | J0HN | F | JR |
| HODGINS | J0HNNY | BURNETTE | <NA> |
| TANNAHILL | J0SEPH | ERIC | <NA> |
| SPRINKLE | L0RI | WOODWARD | <NA> |
| WILLIAMS | M0NIKA | UDANA | <NA> |
| EDMONDS | MARI0N | CAVINESS | <NA> |
| KEENAN | MARY-J0 | <NA> | <NA> |
| SHEPHERD | OTH0 | L | <NA> |
| THOMAS | P0LLY | BROWN | <NA> |
| BLEDSOE | R0Y | JACK | <NA> |
| BUIE | S0NTE | Y | <NA> |
| MITCHELL | SHANN0N | ARLINE | <NA> |
| JOHNSON | T0NYA | BETH | <NA> |
| GRAU | TIM0THY | <NA> | <NA> |
| KENNEDY | V0NCIEAL | LEE | <NA> |
| MOORE | Y0LANDA | RENEE | <NA> |
- 33 first names with zero
- Substitution for letter O
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "0"))
nrow(x)[1] 77x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| NELMS | TROY | 0 | <NA> |
| DEATON | ALICE | 0'CONNOR | <NA> |
| IVESTER | WILLIAM | 0DELL | <NA> |
| MCCULLOCH | JEANNE | 0ROURKE | <NA> |
| HARRELL | DORA | ANN B0YD | <NA> |
| SMITH | BRODY | CO0PER | <NA> |
| LUCK | GENA | DON0HOO | <NA> |
| AMAN | BILLIE | J0 | <NA> |
| BECKERMAN | PENNY | J0NES | <NA> |
| NG | AMY | L0CKAMY | <NA> |
| BRYANT | NATASHA | LAV0NE | <NA> |
| GLOVER | DIONNE | LYNN1820 | <NA> |
| THOMAS | MARCELLA | M0NGE | <NA> |
| JONES | RASHAWN | M0NIQUE | <NA> |
| WHATLEY | LAURA | P0RTER | <NA> |
| ELMORE | BETH | ROBINS0N | <NA> |
| PERKINS | TERESA | ROSENBAUM3305 | <NA> |
| BRADY | SHARON | SAMBRAN0 | <NA> |
| WINSLOW | ANN | TAYL0R | <NA> |
| DAY | TERESS | Y0LONDA | <NA> |
- 77 middle names with zero
- Substitution for letter O
- Some are in superfluous numbers
5.3.2 One
Check for one.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "1"))
nrow(x)[1] 1x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| SATTERFIELD 111 | CHARLES | MASON | <NA> |
- 1 last name with one
- Substitution for I in generation suffix (111 = III)
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "1"))
nrow(x)[1] 0x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|
- 0 first names with one
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "1"))
nrow(x)[1] 39x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| JONES | DONNA | 10052004 | <NA> |
| BENNETT | HAROLD | 11 | <NA> |
| FEATHERSTONE | GEORGE | 111 | <NA> |
| PHAIR | IDELL | 8017 | <NA> |
| BEACHAM | HEATHER | ANDERSON9104576 | <NA> |
| KOERNER | JENNIFER | ANN155 | <NA> |
| BRODIE | WILLIAM | C1010 | <NA> |
| EDWARDS | FRANK | D 11 | <NA> |
| HOWERIN | MICHAEL | DALE401 | <NA> |
| HUNTER | MORDECAI | J1-TO | <NA> |
| FAICLOTH | TIMOTHY | LOUIS7100 | <NA> |
| GLOVER | DIONNE | LYNN1820 | <NA> |
| GUIDO | DEANA | LYNN2513 | <NA> |
| BECHTEL | TERESA | MARIE103062 | <NA> |
| BREEN | TERRANCE | MICHAEL146 | <NA> |
| PATTERSON | CARLA | NADINE DOUGLAS1 | <NA> |
| PLESS | JOAN | WRIGHT2106 | <NA> |
- 39 middle names with one
- Some are substitution for I in generation suffix
- Some are in superfluous numbers
5.3.3 Other digits
Check for other digits.
x <- d %>%
dplyr::filter(stringr::str_detect(last_name, "[2-9]"))
nrow(x)[1] 1x %>%
dplyr::distinct(last_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(last_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| ALBER5TSON | BASIL | ERVIN | <NA> |
- 1 last name with digits 2-9
- Random insertion
x <- d %>%
dplyr::filter(stringr::str_detect(first_name, "[2-9]"))
nrow(x)[1] 2x %>%
dplyr::distinct(first_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(first_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| SPIVEY | FR4ANK | THOMAS | SR |
| CHILTON | J8IMMIE | HERBERT | <NA> |
- 2 first names with digits 2-9
- Look like random insertions
x <- d %>%
dplyr::filter(stringr::str_detect(midl_name, "[2-9]"))
nrow(x)[1] 24x %>%
dplyr::distinct(midl_name, .keep_all = TRUE) %>%
dplyr::slice_sample(n = 20) %>%
dplyr::arrange(midl_name) %>%
dplyr::select(all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|
| JONES | DONNA | 10052004 | <NA> |
| SODAGAR | EASA | 2205 | <NA> |
| WILLIS | DEJUAN | 328 | <NA> |
| YOUNG | WANWYNE | 4625 | <NA> |
| CLARKE | MINERVA | 4932 | <NA> |
| PHAIR | IDELL | 8017 | <NA> |
| FRENCH | SHNETTA | ALEXANDER080572 | <NA> |
| SHUMAKER | RUTH | ANN BURTON47 | <NA> |
| KOERNER | JENNIFER | ANN155 | <NA> |
| WARD | EVA | B2957 | <NA> |
| HOWERIN | MICHAEL | DALE401 | <NA> |
| FAICLOTH | TIMOTHY | LOUIS7100 | <NA> |
| GLOVER | DIONNE | LYNN1820 | <NA> |
| BECHTEL | TERESA | MARIE103062 | <NA> |
| HILL | ZEB | MITCHELL368 | <NA> |
| BLAIR | ESSIE | MIZELLE25248249 | <NA> |
| PERKINS | TERESA | ROSENBAUM3305 | <NA> |
| PYRTLE | PHILLIP | W5RAY | SR |
| SMITH | TRACY | WAYNE030986 | <NA> |
| PLESS | JOAN | WRIGHT2106 | <NA> |
- 24 middle names with digits 2-9
- One random insertion
- Most appear to be superfluous numbers (from the address?)
5.4 Special words
Look for special words that shouldn’t be in names.
Define word patterns to search for.
# honorifics
w_hons <- c(
"MR", "MISTER", "MASTER", "MRS", "MS", "MISS",
"REV", "REVEREND", "SR", "SISTER", "BR", "BROTHER",
"FATHER", "MOTHER", "PASTOR", "ELDER", "BISHOP",
"DR", "DOCTOR", "MD", "PROF", "PROFESSOR"
)
# generation suffixes
w_gen <- c(
"JR", "JNR", "JUNIOR", "SR", "SNR", "SENIOR",
"1ST", "2ND", "3RD", "4TH", "5TH", "6TH", "7TH", "8TH",
"FIRST", "SECOND", "THIRD", "FOURTH", "FIFTH", "SIXTH", "SEVENTH", "EIGHTH", "EIGHTTH",
"1", "2", "3", "4", "5", "6", "7", "8",
"I", "II", "III", "IIII", "IV", "V", "VI"
)
# special values
w_spec <- c(
"NN", "NMN", "NAME",
"UNK", "UNKNOWN", "AKA", "KNOWN AS", "ALSO KNOWN AS", "ALIAS",
"BLIND"
)
# test
w_test <- c(
"TEST", "TST", "DUMMY", "VOTER", "([A-Z])\\1{2,}"
)5.4.1 Last name
# regular expression to match words
w_regexp <-
c(w_hons, w_gen, w_spec, w_test) %>% # all special words
unique() %>% # make it a set
dplyr::setdiff( # remove words that appear to mostly be validly used
c(
"BISHOP",
"BLIND",
"BROTHER",
"DOCTOR",
"ELDER",
"FIRST",
"JUNIOR",
"MASTER",
"MISS",
"MISTER",
"NAME",
"PASTOR",
"SENIOR",
"TEST",
"THIRD",
"VOTER"
)
) %>%
glue::glue(x = . , "\\b{x}\\b") %>% # must be words
glue::glue_collapse(sep = "|") # search for any
x <- d %>%
dplyr::mutate(
match =
last_name %>%
stringr::str_to_upper() %>%
stringr::str_replace_all(pattern = "[^ A-Z]", replacement = " ") %>%
stringr::str_squish() %>%
stringr::str_extract(pattern = w_regexp)
) %>%
dplyr::filter(!is.na(match))
nrow(x)[1] 119x %>%
dplyr::arrange(match, sex, last_name, first_name) %>%
dplyr::select(match, sex, age, all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| match | sex | age | last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|---|---|---|
| DR | MALE | 43 | WILLIAMSON DR | IRVIN | D | <NA> |
| I | FEMALE | 37 | I'ANSON-JACKSON | JENNIFER | <NA> | <NA> |
| II | MALE | 24 | BIREN II | WILLIAM | GEORGE | <NA> |
| II | MALE | 22 | CRITTENDON II | WILLIAM | BURRELL | <NA> |
| II | MALE | 45 | EVANS II | DONALD | M | <NA> |
| II | MALE | 53 | FILLINGHAM, II | ROBERT | E | <NA> |
| II | MALE | 28 | GOODWIN II | PAUL | J | <NA> |
| II | MALE | 57 | GREEN II | BILLY | HOWARD | <NA> |
| II | MALE | 39 | METTS II | CAREY | MONTGOMERY | <NA> |
| II | MALE | 33 | MILHORN II | JOSEPH | JAMES | <NA> |
| II | MALE | 26 | PERSON II | DARYEL | JAMES | <NA> |
| II | MALE | 34 | SEABOLD II | GERALD | W | <NA> |
| II | MALE | 46 | STANLEY II | WILLIAM | A | <NA> |
| II | MALE | 34 | TAYLOR II | ROBERT | D | <NA> |
| II | MALE | 32 | THOMBS II | DANIEL | EUGENE | <NA> |
| II | MALE | 33 | WATSON II | ROBERT | NATHANIEL | <NA> |
| II | MALE | 32 | WORD II | JOE | NAHAN | <NA> |
| III | MALE | 59 | AUSLEY III | PRESTON | ALEXANDER | <NA> |
| III | MALE | 34 | BEATTY III | CURTIS | M | <NA> |
| III | MALE | 57 | BLACKWELDER III | DWIGHT | MCNAIRY | <NA> |
| III | MALE | 47 | BOONE III | JAMES | HENRY | <NA> |
| III | MALE | 22 | BOSQUEZ III | RICHARD | <NA> | <NA> |
| III | MALE | 39 | CHAPPELL III | TRAVIS | <NA> | <NA> |
| III | MALE | 22 | COCKERHAM III | BOBBY | LEE | <NA> |
| III | MALE | 59 | CONNELL III | THOMAS | JOSEPH | <NA> |
| III | MALE | 57 | FAULKNER III | HOWARD | VERNON | <NA> |
| III | MALE | 18 | GOODWIN III | WARD | ALEXANDER | <NA> |
| III | MALE | 38 | GROUSE III | CHARLES | J | <NA> |
| III | MALE | 45 | HARRIS III | WILLIAM | T | <NA> |
| III | MALE | 44 | KNOX III | JOHN | J | <NA> |
| III | MALE | 58 | LANE III | WILLIAM | JAMES | <NA> |
| III | MALE | 62 | MCGUIRT III | JAMES | WILLIAM | <NA> |
| III | MALE | 25 | MILLER III | JOHNNIE | H | <NA> |
| III | MALE | 41 | MOORE III | JAMES | P | <NA> |
| III | MALE | 33 | NEWSOME III | THOMAS | LESLIE | <NA> |
| III | MALE | 27 | PEACOCK III | EDWARD | JACKSON | <NA> |
| III | MALE | 53 | PETERS III | MARION | HOWELL | <NA> |
| III | MALE | 48 | PRUDEN III | THOMAS | EUGENE | <NA> |
| III | MALE | 23 | REDFEARN III | WILBERT | <NA> | <NA> |
| III | MALE | 35 | SMITH III | GUY | R | <NA> |
| III | MALE | 67 | THOMPSON III | EMERY | <NA> | <NA> |
| IIII | MALE | 48 | BAKER IIII | WILLAIM | RAINEY | <NA> |
| IV | MALE | 25 | BUXTON IV | SAMUEL | R | <NA> |
| IV | MALE | 25 | LONG IV | FLOYD | M | <NA> |
| IV | MALE | 31 | THOMPSON IV | HARRY | M | <NA> |
| JR | MALE | 47 | ANSELMENT JR | JOSEPH | LEONARD | <NA> |
| JR | MALE | 35 | BALL JR | SAMUEL | LEE | <NA> |
| JR | MALE | 57 | BARKLEY JR | CHARLES | W | <NA> |
| JR | MALE | 59 | BENDER JR | JOHN | JOHN P | <NA> |
| JR | MALE | 32 | BINGHAM JR. | AMES | EDMOND | <NA> |
| JR | MALE | 61 | BIRCHFIELD JR | MILBURN | JOEL | <NA> |
| JR | MALE | 55 | BLEDSOE JR | HOMER | BLAINE | <NA> |
| JR | MALE | 33 | BROWN JR | ROBERT | A | <NA> |
| JR | MALE | 58 | BUNDESMAN JR | BERNARD | B | <NA> |
| JR | MALE | 36 | BYRD JR | HERBERT | L | <NA> |
| JR | MALE | 54 | CAIL JR | MALCOLM | LEHOLMES | <NA> |
| JR | MALE | 65 | CARRIER JR | ROBERT | WILSON | <NA> |
| JR | MALE | 25 | CHAMBERS JR | KENNETH | RAY | <NA> |
| JR | MALE | 41 | CHARLES JR | WILLIE | J | <NA> |
| JR | MALE | 46 | CLAY JR | WILEY | WALTON | JR |
| JR | MALE | 36 | CLAYTON JR | JAMES | D | <NA> |
| JR | MALE | 73 | CULBRETH JR | WALTER | E | <NA> |
| JR | MALE | 31 | DAYE JR. | JAMES | <NA> | JR |
| JR | MALE | 36 | ENGLISH JR | WARREN | ROBERT | <NA> |
| JR | MALE | 56 | EVANS JR | RALPH | <NA> | II |
| JR | MALE | 34 | FAILLE JR | EDWARD | J | <NA> |
| JR | MALE | 27 | FARMER JR | BENJAMIN | STEVE | <NA> |
| JR | MALE | 39 | FRAZIER JR | JAMES | A | <NA> |
| JR | MALE | 44 | GARCIA JR | FRANK | <NA> | <NA> |
| JR | MALE | 24 | HALL JR | JAMES | B | <NA> |
| JR | MALE | 53 | HARDIN JR | CHARLES | ELMORE | <NA> |
| JR | MALE | 58 | HARGRAVES JR | JAMES | CALVIN | <NA> |
| JR | MALE | 34 | HARRIS JR | CHAMP | <NA> | <NA> |
| JR | MALE | 36 | HAWKINS JR | REED | GREGORY | <NA> |
| JR | MALE | 32 | HENSLEY JR | LAWRENCE | G | <NA> |
| JR | MALE | 59 | HERNDON JR | EVERETT | GEORGE | <NA> |
| JR | MALE | 43 | HILL JR | JAMES | C | <NA> |
| JR | MALE | 27 | HOYLE JR | GEORGE | A | <NA> |
| JR | MALE | 23 | HUMPHRIES JR | DONNIE | R | <NA> |
| JR | MALE | 34 | KENNEDY JR | THOMAS | E | <NA> |
| JR | MALE | 40 | KUBU JR | JERRY | JOHN | <NA> |
| JR | MALE | 47 | LANE JR | DAVID | C | <NA> |
| JR | MALE | 53 | LAWRENCE JR | HARRY | <NA> | <NA> |
| JR | MALE | 35 | MARBLE JR | ROBERT | STERLING | <NA> |
| JR | MALE | 27 | MCCLURE JR | DONALD | R | <NA> |
| JR | MALE | 35 | MCGUIRE JR | JOHN | M | <NA> |
| JR | MALE | 33 | MONGIOVI JR | ANTHONY | B | <NA> |
| JR | MALE | 62 | MOORE JR | HARRY | GRADY | <NA> |
| JR | MALE | 51 | MORRISON JR | WILLIAM | EMERSON | <NA> |
| JR | MALE | 20 | MOSES JR | MICHAEL | WILLIAM | <NA> |
| JR | MALE | 33 | NASIFE JR | SAMUEL | NICHOLAS | <NA> |
| JR | MALE | 47 | OUTLAND JR | HOWARD | BROWN | <NA> |
| JR | MALE | 22 | OVERTON JR | ROBERT | ALLEN | <NA> |
| JR | MALE | 19 | PARKS JR | JOEL | TIMOTHY | <NA> |
| JR | MALE | 66 | PULSIFER JR | HAROLD | WINFRED | <NA> |
| JR | MALE | 43 | REED JR | BRUCE | HAL | <NA> |
| JR | MALE | 74 | ROBERTS JR | GEORGE | MARION | <NA> |
| JR | MALE | 36 | RUSSELL, JR. | KERMITT | PATRICK | <NA> |
| JR | MALE | 68 | SHADE JR | EVERETTE | LEE | <NA> |
| JR | MALE | 55 | SHEALLY JR | WILLIAM | B | <NA> |
| JR | MALE | 82 | ST JEAN JR | JOSEPH | <NA> | <NA> |
| JR | MALE | 25 | STANSBERRY JR | DAVID | R | <NA> |
| JR | MALE | 24 | STREETER JR | THOMAS | EARL | <NA> |
| JR | MALE | 44 | VAN DOREN JR | EDWARD | FOSTER | <NA> |
| JR | MALE | 36 | WHITEHOUSE JR | JOHN | JOSEPH | <NA> |
| JR | MALE | 32 | WHITFIELD JR | RAYMOND | E | <NA> |
| JR | MALE | 40 | WIEGOLD JR | RICHARD | MARTIN | <NA> |
| JR | MALE | 33 | WILLIAMSON JR | SOLOMAN | J | <NA> |
| JR | MALE | 41 | YOAKUM JR | JC | <NA> | <NA> |
| MD | FEMALE | 40 | SMITH MD | PATRICIA | ANN | <NA> |
| SR | FEMALE | 50 | BRAKE SR ESS | CAROLYN | G | <NA> |
| SR | MALE | 45 | DOSS SR | MICHAEL | RAY | <NA> |
| SR | MALE | 87 | HICKS SR | WILFORD | LYTLE | SR. |
| SR | MALE | 60 | STIMSON SR | RICHARD | BARRETT | <NA> |
| SR | MALE | 78 | VAUGHN SR | WALTER | S | <NA> |
| SR | MALE | 30 | WHITWORTH SR | RANDY | SEAN | <NA> |
| V | FEMALE | 26 | V'SOSKE | ERIKA | DONNELL | <NA> |
| V | MALE | 26 | MOODY V | WILLIE | HOLMES | <NA> |
| V | MALE | 31 | TENNENT V | EDWARD | S | <NA> |
I eyeballed the results and removed words (using setdiff in the code above) which appeared to be mostly
validly used.
Invalid words:
- Most appear to be a suffix code added into the last name
5.4.2 First name
# regular expression to match words
w_regexp <-
c(w_hons, w_gen, w_spec, w_test) %>% # all special words
unique() %>% # make it a set
dplyr::setdiff( # remove words that appear to mostly be validly used
c(
"BISHOP",
"BROTHER",
"DOCTOR",
"ELDER",
"JUNIOR",
"MASTER",
"MISTER",
"PASTOR",
"PROFESSOR"
)
) %>%
glue::glue(x = . , "\\b{x}\\b") %>% # must be words
glue::glue_collapse(sep = "|") # search for any
x <- d %>%
dplyr::mutate(
match =
first_name %>%
stringr::str_to_upper() %>%
stringr::str_replace_all(pattern = "[^ A-Z]", replacement = " ") %>%
stringr::str_squish() %>%
stringr::str_extract(pattern = w_regexp)
) %>%
dplyr::filter(!is.na(match))
nrow(x)[1] 328x %>%
dplyr::arrange(match, sex, last_name, first_name) %>%
dplyr::select(match, sex, age, all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| match | sex | age | last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|---|---|---|
| DR | FEMALE | 55 | AAL-ANUBIAIMHOTE | DR NGOZI | <NA> | <NA> |
| FATHER | MALE | 78 | WILMES | FATHER | JAMES | <NA> |
| I | FEMALE | 55 | ARMOUR | I ELISABETH | <NA> | <NA> |
| I | FEMALE | 24 | BOYKIN-PRIDE | I'MAN | BRIANN | <NA> |
| I | FEMALE | 33 | BRADLEY | I-ASIA | VICTORIA-CHERIS | <NA> |
| I | FEMALE | 46 | BRITTON | I-CHI | GUO | <NA> |
| I | FEMALE | 19 | BROOME | I SONYA | TIERRA | <NA> |
| I | FEMALE | 50 | BULLARD | NANCY I | W | <NA> |
| I | FEMALE | 105 | CARLYLE | I | E | <NA> |
| I | FEMALE | 29 | CARTER | I JEANNETTE | GUILBE | <NA> |
| I | FEMALE | 32 | CHANG | I-WEN | <NA> | <NA> |
| I | FEMALE | 38 | COLEMAN | JANA'I | D | <NA> |
| I | FEMALE | 35 | CSEH | MON I | WANG | <NA> |
| I | FEMALE | 69 | DESROSIERS | I | DARLENE | <NA> |
| I | FEMALE | 52 | DOSHI | I | <NA> | <NA> |
| I | FEMALE | 34 | ERVIN | I MEI | CHOU | <NA> |
| I | FEMALE | 47 | GAYE | I COLEEN | M | <NA> |
| I | FEMALE | 73 | GLASPIE | I | CHARLOTTE | <NA> |
| I | FEMALE | 105 | GREEN | I | A | <NA> |
| I | FEMALE | 28 | HALL | I'MESHA | L | <NA> |
| I | FEMALE | 60 | HEYWARD | I | CARTER | <NA> |
| I | FEMALE | 42 | HU | EDNA I | JEN | <NA> |
| I | FEMALE | 53 | HUNEYCUTT | I | SUZANNE EUDY | <NA> |
| I | FEMALE | 46 | JAN | I-RAN | HO | <NA> |
| I | FEMALE | 42 | KUEHR-MCLAREN | I | WENDY | <NA> |
| I | FEMALE | 96 | LANE | I | E MRS | <NA> |
| I | FEMALE | 29 | LEWIS | LEISA I | OITERONG | <NA> |
| I | FEMALE | 105 | MARTIN | I | MARY | <NA> |
| I | FEMALE | 43 | MENG | CHENG-I | C | <NA> |
| I | FEMALE | 19 | MOORING | I'RISHA | ORCHA' | <NA> |
| I | FEMALE | 38 | MORRIS | I LANE | <NA> | <NA> |
| I | FEMALE | 35 | MULLIS | LISA I | BELL | <NA> |
| I | FEMALE | 105 | NEAL | I | M | <NA> |
| I | FEMALE | 51 | PERRY | I | SUN | <NA> |
| I | FEMALE | 28 | POPE | I-ASIA | COX | <NA> |
| I | FEMALE | 96 | ROSS | I | G MRS | <NA> |
| I | FEMALE | 46 | SAUNDERS | VICKI I | SUTTON | <NA> |
| I | FEMALE | 23 | SHERWOOD | I-LI | BETH | <NA> |
| I | FEMALE | 29 | SIMMONS | I-EESHA | D | <NA> |
| I | FEMALE | 34 | SIU | I-MEI | <NA> | <NA> |
| I | FEMALE | 70 | SOUTHERLAND | I | KATHLEEN | <NA> |
| I | FEMALE | 71 | SUMMEY | I | V | <NA> |
| I | FEMALE | 53 | SUTARIA | DEBORAH I | S | <NA> |
| I | FEMALE | 31 | TAI | CHIH-I | <NA> | <NA> |
| I | FEMALE | 79 | TUTTLE | I | BESSIE | <NA> |
| I | FEMALE | 85 | WASHINGTON | CAROLINE I | HALEY | <NA> |
| I | FEMALE | 37 | WEIR | I | SUN | <NA> |
| I | FEMALE | 23 | WILEY | I'AIESHA | SHANTEA | <NA> |
| I | FEMALE | 79 | WOOD | I | F | JR |
| I | MALE | 88 | ARNOLD | I | B | <NA> |
| I | MALE | 42 | BATES | I | C | <NA> |
| I | MALE | 69 | BREWER | I | V | <NA> |
| I | MALE | 72 | CALDWELL | I | M | <NA> |
| I | MALE | 66 | CHEO | I-DEH | <NA> | <NA> |
| I | MALE | 40 | CLARKE | I | MITCHELL | <NA> |
| I | MALE | 72 | COLLEY | I | D | <NA> |
| I | MALE | 82 | DOWNS | I V | <NA> | <NA> |
| I | MALE | 81 | EDWARDS | I | J | JR |
| I | MALE | 79 | FERGUSON | I | M | JR |
| I | MALE | 36 | FU | I-KONG | BATOR | <NA> |
| I | MALE | 105 | GORDON | I | BRYCE | <NA> |
| I | MALE | 80 | GUNTER | I | W | <NA> |
| I | MALE | 69 | HAIG | I REID | S | <NA> |
| I | MALE | 51 | HICKS | I FAISON | <NA> | <NA> |
| I | MALE | 56 | HINES | I | ALAN | <NA> |
| I | MALE | 83 | HOOD | I | G | <NA> |
| I | MALE | 80 | HOWARD | I | CLARENCE | <NA> |
| I | MALE | 25 | JENKINS | I | D | III |
| I | MALE | 64 | JOHNSON | I | M | <NA> |
| I | MALE | 75 | JOHNSTON | I | C | <NA> |
| I | MALE | 80 | KELLY | I | PERRY | <NA> |
| I | MALE | 60 | KINLAW | I | W | <NA> |
| I | MALE | 71 | LAKE | I | BEVERLY | JR |
| I | MALE | 77 | LITTLE | I | MAYO | JR |
| I | MALE | 83 | LONGMUIR | I | S | <NA> |
| I | MALE | 41 | LYONS | I | CHARLES | <NA> |
| I | MALE | 204 | MANESS | I | M | <NA> |
| I | MALE | 63 | MCNEIL | I | J | <NA> |
| I | MALE | 70 | MILLER | I | J | <NA> |
| I | MALE | 26 | MILLER | I | D MCGILVRAY | <NA> |
| I | MALE | 60 | PALMER | I | JEREMIAH | <NA> |
| I | MALE | 88 | PATTERSON | I | EUGENE | <NA> |
| I | MALE | 62 | PAUL | I | B | <NA> |
| I | MALE | 82 | PLYLER | I | F | JR |
| I | MALE | 65 | POPE | I | H | JR |
| I | MALE | 62 | POWELL | I | HILL | <NA> |
| I | MALE | 44 | POWELL | STEVEN I | VANROOY | <NA> |
| I | MALE | 73 | QUINN | I | J | <NA> |
| I | MALE | 43 | QUINN | I | J | JR |
| I | MALE | 56 | RUSS | I | V | <NA> |
| I | MALE | 84 | SMITH | I | BRUCE | <NA> |
| I | MALE | 54 | SMITH | I | MELVIN | <NA> |
| I | MALE | 105 | SOLOMON | I | S | <NA> |
| I | MALE | 76 | STONE | I | L | <NA> |
| I | MALE | 31 | TERRY | I | B | III |
| I | MALE | 75 | TRAVIS | I | A | <NA> |
| I | MALE | 55 | WAKEFIELD | I | NELSON | <NA> |
| I | MALE | 80 | WALLACE | I | J | <NA> |
| I | MALE | 95 | WARREN | I | <NA> | <NA> |
| I | MALE | 26 | WU | I-CHAN | JOHN | <NA> |
| III | MALE | 57 | MANUEL | WALTER III | <NA> | <NA> |
| III | MALE | 36 | MCPHERSON | VAN III | <NA> | <NA> |
| III | MALE | 62 | NASH | SAMUEL III | <NA> | <NA> |
| III | MALE | 58 | PATALANO | LOUIS III | <NA> | <NA> |
| III | MALE | 42 | SCOTT | CALVIN III | <NA> | <NA> |
| III | MALE | 49 | SILVER | III | HAYDEN | <NA> |
| IV | MALE | 30 | COPELAND | IV | EDWARD JAMES | <NA> |
| JR | MALE | 71 | ANDERSON | ELBERT JR | <NA> | <NA> |
| JR | MALE | 39 | BARNEY | LEO JR | <NA> | <NA> |
| JR | MALE | 82 | BOWLES | ROBERT JR | <NA> | <NA> |
| JR | MALE | 50 | BRYANT | FREDDIE JR | <NA> | <NA> |
| JR | MALE | 50 | COLLINS | JACK JR | <NA> | <NA> |
| JR | MALE | 66 | DARRELL | JAMES JR | <NA> | <NA> |
| JR | MALE | 52 | DAVIS | HENRY JR | <NA> | <NA> |
| JR | MALE | 53 | GERTZ | JR | RICHARD | <NA> |
| JR | MALE | 51 | HOAGLAND | JR | SANDY | <NA> |
| JR | MALE | 49 | HOLLEY | JR | JOHN MARSHAL | <NA> |
| JR | MALE | 42 | JONES | JR | MICHAEL | <NA> |
| JR | MALE | 42 | JOYNER | JR | EARNEST | <NA> |
| JR | MALE | 56 | MCADAMS | WILL,JR | <NA> | <NA> |
| JR | MALE | 67 | MCCLELLAND | ERNEST JR | <NA> | <NA> |
| JR | MALE | 46 | MCCOY | JR | RICHARD TUNN | <NA> |
| JR | MALE | 62 | MCIVER | SIM JR | <NA> | <NA> |
| JR | MALE | 70 | MCLEOD | WILLIE JR | <NA> | <NA> |
| JR | MALE | 70 | MULL | MADISON JR | <NA> | <NA> |
| JR | MALE | 59 | PALMS | DONALD JR | <NA> | <NA> |
| JR | MALE | 67 | PEOPLES | LONZO JR | <NA> | <NA> |
| JR | MALE | 50 | ROSADO | ALEJANDRO JR | <NA> | <NA> |
| JR | MALE | 56 | THOMPSON | JOSEPHUS JR | <NA> | <NA> |
| JR | MALE | 57 | TILLMAN | BENNIE JR | <NA> | <NA> |
| JR | MALE | 64 | TOOLE | JR | <NA> | <NA> |
| JR | MALE | 63 | WOODS | HOUSTON JR | <NA> | <NA> |
| MD | MALE | 50 | STOCKELL | MD | COOPER | III |
| MISS | FEMALE | 31 | SPEIGHT | MISS STEPHANI | RENEE' | <NA> |
| MR | MALE | 43 | FATE | MR | <NA> | <NA> |
| MR | MALE | 34 | KANE | MR | <NA> | <NA> |
| MRS | FEMALE | 79 | BECK | MRS WILLIAM | E | <NA> |
| MRS | FEMALE | 68 | BINGMAN | GRAY MRS | <NA> | <NA> |
| MRS | FEMALE | 69 | BURKE | MRS GEORGE | W | <NA> |
| MRS | FEMALE | 73 | CARTER | PAUL MRS | <NA> | JR |
| MRS | FEMALE | 86 | CHATMAN | MRS H | L | <NA> |
| MRS | FEMALE | 0 | COVINGTON | EDNA(MRS | PERRY, JR) | <NA> |
| MRS | FEMALE | 78 | CROMER | BETTY MRS | A | <NA> |
| MRS | FEMALE | 90 | DAVENPORT | MRS H | T | <NA> |
| MRS | FEMALE | 68 | DODSON | RAY MRS | <NA> | <NA> |
| MRS | FEMALE | 81 | EATON | MRS JOHN | C | <NA> |
| MRS | FEMALE | 82 | ESTES | ALMA MRS | A | <NA> |
| MRS | FEMALE | 90 | FIELDS | MRS G | CLINTON | <NA> |
| MRS | FEMALE | 84 | FIELDS | MRS JAMES | C | <NA> |
| MRS | FEMALE | 78 | FULP | JAMES MRS | C | <NA> |
| MRS | FEMALE | 78 | GIBSON | H MRS | L | <NA> |
| MRS | FEMALE | 79 | GOOLSBY | EUGENE MRS | <NA> | <NA> |
| MRS | FEMALE | 85 | GURGANIOUS | JOHN MRS | HALLIE | <NA> |
| MRS | FEMALE | 84 | HAMRICK | JOHN R MRS | MARGARET | <NA> |
| MRS | FEMALE | 75 | HARRIS | MRS FRED | W | <NA> |
| MRS | FEMALE | 104 | HARRIS | MRS P | D | <NA> |
| MRS | FEMALE | 61 | HARRIS | MRS WILLIAM | W | <NA> |
| MRS | FEMALE | 77 | HARTIS | FRANK E MRS | THAMES | <NA> |
| MRS | FEMALE | 104 | HOLLIDAY | MRS JOSEPH | <NA> | <NA> |
| MRS | FEMALE | 74 | JEFFERSON | MRS ATHOL | G | <NA> |
| MRS | FEMALE | 74 | JOHNSON | MRS CLYDE | W | <NA> |
| MRS | FEMALE | 82 | LAMB | WILSON MRS | C | <NA> |
| MRS | FEMALE | 63 | LARIMORE | WILLIAM MRS | <NA> | <NA> |
| MRS | FEMALE | 54 | LUU | MRS | <NA> | <NA> |
| MRS | FEMALE | 62 | MABE | STEVE MRS | <NA> | <NA> |
| MRS | FEMALE | 70 | MARTIN | JAMES MRS | H | <NA> |
| MRS | FEMALE | 71 | MASSAGEE | JAMES H MRS | SUE | <NA> |
| MRS | FEMALE | 98 | MOODY | MRS WILLARD | W | <NA> |
| MRS | FEMALE | 82 | MORGAN | MRS ROY | A | <NA> |
| MRS | FEMALE | 92 | NICHOLS | DORIS ( MRS W | <NA> | <NA> |
| MRS | FEMALE | 68 | POPE | MRS O | N | JR |
| MRS | FEMALE | 86 | REICH | MRS LESTER | G | <NA> |
| MRS | FEMALE | 92 | RHONEY | ROBERT MRS | T | <NA> |
| MRS | FEMALE | 71 | RIVES | MRS WILBUR | A | <NA> |
| MRS | FEMALE | 69 | SCALES | BETTY MRS | H | <NA> |
| MRS | FEMALE | 72 | SMITH | MRS WILLIAM JOE | DAVIS | <NA> |
| MRS | FEMALE | 75 | TIMMONS | THOMAS MRS | E | <NA> |
| MRS | FEMALE | 75 | TRULL | JAMES MRS | T | <NA> |
| MRS | FEMALE | 89 | WARD | MARVIN MRS | M | <NA> |
| MRS | FEMALE | 86 | WHITE | JOE MRS | MRS | <NA> |
| MRS | FEMALE | 78 | WOODLEY | MRS WALLACE | ( RUTH ) | <NA> |
| NMN | FEMALE | 61 | QUEEN | GERALDINE(NMN | <NA> | <NA> |
| NMN | MALE | 61 | BORDERS | EUGENE(NMN) | <NA> | <NA> |
| NMN | MALE | 62 | FOSTER | OTIS(NMN) | JR | <NA> |
| REV | MALE | 83 | FEATHERSTONE | REV. ROBERT | A | <NA> |
| SISTER | FEMALE | 69 | GILDEA | SISTER | THERESINE | <NA> |
| SISTER | FEMALE | 71 | KELLY | SISTER | ANN | <NA> |
| SISTER | FEMALE | 47 | PEGUESE | SISTER | GIRTRUE | <NA> |
| SISTER | FEMALE | 79 | ROSS | SISTER | S | <NA> |
| SISTER | FEMALE | 73 | TANCRAITOR | SISTER MAXINE | ELIZABETH | <NA> |
| SR | MALE | 0 | DUNTON | JULIAN SR | <NA> | <NA> |
| SR | MALE | 60 | GRAHAM | STEPHEN SR | LEGREE | <NA> |
| SR | MALE | 71 | PHILLIPS | SR | DAYLE KELLEY | <NA> |
| V | FEMALE | 51 | ADAMS | V | JAN | <NA> |
| V | FEMALE | 66 | ANDERSON | V | RUTH K | <NA> |
| V | FEMALE | 52 | BATKIN | V | MARIA | <NA> |
| V | FEMALE | 52 | BENFIELD | RHONDA V | <NA> | <NA> |
| V | FEMALE | 63 | BOWDEN | V | RUTH | <NA> |
| V | FEMALE | 84 | BOYD | V | MARIE | <NA> |
| V | FEMALE | 61 | BRANDT | V | KATHLEEN GRY | <NA> |
| V | FEMALE | 42 | CALHOUN | V | ANNE | <NA> |
| V | FEMALE | 79 | CARLAND | V | ANN | <NA> |
| V | FEMALE | 76 | CARTER | PAUL V | MRS | <NA> |
| V | FEMALE | 72 | CAVENDER | V | DORIS | <NA> |
| V | FEMALE | 90 | COOK | INEZ V | CARY | <NA> |
| V | FEMALE | 58 | DALBERG | V | ANDREA | <NA> |
| V | FEMALE | 83 | DOTY | V'ONA | GILBERT | <NA> |
| V | FEMALE | 83 | EDWARDS | V | ERLINE | <NA> |
| V | FEMALE | 56 | EVANS-SMITH | V MARIE | HUMPHERY | <NA> |
| V | FEMALE | 56 | FINLEY | V | ANNE | <NA> |
| V | FEMALE | 38 | FUTRELL | V JEANINE | BOWDEN | <NA> |
| V | FEMALE | 91 | GIBBS | V | WILLA | <NA> |
| V | FEMALE | 20 | GLENN | V'SHATAVIA | D | <NA> |
| V | FEMALE | 40 | HALL | CATHEDRIA V | HOOKER | <NA> |
| V | FEMALE | 74 | HALL | V | JUANITA | <NA> |
| V | FEMALE | 60 | HAMILTON | V KAYE | <NA> | <NA> |
| V | FEMALE | 52 | JAYANTY | LAKSHMI S V | S | <NA> |
| V | FEMALE | 69 | JOHNSON | V | JOLINE | <NA> |
| V | FEMALE | 83 | KENNEDY | V0NCIEAL | LEE | <NA> |
| V | FEMALE | 105 | KRITES | V | C | <NA> |
| V | FEMALE | 81 | LANCASTER | ALDA V | LIMBAUGH | <NA> |
| V | FEMALE | 75 | LEE | V | JUANITA | <NA> |
| V | FEMALE | 0 | LEE | V | FLORENCE | <NA> |
| V | FEMALE | 83 | LYONS | V | BETTIE | <NA> |
| V | FEMALE | 80 | MARSHALL | CALLIE V. | LUTZ | <NA> |
| V | FEMALE | 0 | MAYBERRY | V | JACQUELINE | <NA> |
| V | FEMALE | 61 | MOCK | V CHARLENE | D | <NA> |
| V | FEMALE | 52 | MOORMAN | V | E | <NA> |
| V | FEMALE | 44 | MORTON | SANDRA V | GOSNELL | <NA> |
| V | FEMALE | 53 | OSLEY | V | BONITA NAFZIGER | <NA> |
| V | FEMALE | 55 | OWENSBY | V | ANN | <NA> |
| V | FEMALE | 79 | PAYNE | V | LUCILLE | <NA> |
| V | FEMALE | 60 | PERERA | V | MALLIKA | <NA> |
| V | FEMALE | 85 | POWELL | V | ESTELLE | <NA> |
| V | FEMALE | 86 | RASH | V | ANDERSON | <NA> |
| V | FEMALE | 105 | RAY | V | FRANCIS | <NA> |
| V | FEMALE | 40 | SEMONCHE | LAURA V | A | <NA> |
| V | FEMALE | 46 | SHAFFER | V LYNNE | STRICKLAND | <NA> |
| V | FEMALE | 92 | SHELF | V | S MRS | <NA> |
| V | FEMALE | 55 | SMELTZER | V | DIANE | <NA> |
| V | FEMALE | 81 | SMITH | V | RAE | <NA> |
| V | FEMALE | 61 | STANTON | V | GAYLE | <NA> |
| V | FEMALE | 41 | STERLING | V | LEE | <NA> |
| V | FEMALE | 61 | STODDARD | V | CHRISTIVE | <NA> |
| V | FEMALE | 54 | STREIFF | CONNIE V | R | <NA> |
| V | FEMALE | 35 | TEAGUE | V | MICHELLE | <NA> |
| V | FEMALE | 58 | TERRY | CAROLYN V | MASK | <NA> |
| V | FEMALE | 50 | THOMPSON | V | DELORES | <NA> |
| V | FEMALE | 50 | TINNEY | V | LEE W | <NA> |
| V | FEMALE | 60 | VANNOY | V | GAIL | <NA> |
| V | FEMALE | 59 | WAGGONER | V | C | <NA> |
| V | FEMALE | 69 | WALKER | V | FRANCES | <NA> |
| V | FEMALE | 67 | WHITE | V CAROLE | <NA> | <NA> |
| V | FEMALE | 44 | WILLIAMS | JACQUELYNE V. | MOORE | <NA> |
| V | FEMALE | 86 | WRIGHT | O V | LEDFORD | <NA> |
| V | MALE | 58 | ADAMS | A V | <NA> | <NA> |
| V | MALE | 72 | ADAMS | V | WAYNE | <NA> |
| V | MALE | 97 | ALLEN | V | B | <NA> |
| V | MALE | 73 | AVVA | V | SARMA | <NA> |
| V | MALE | 45 | BARBOUR | V | KEITH | <NA> |
| V | MALE | 85 | BAZEMORE | V | S | <NA> |
| V | MALE | 69 | BOWMAN | V | C | <NA> |
| V | MALE | 60 | BOYKIN | V | RAYMOND | JR |
| V | MALE | 74 | CLINE | V | OTHO | JR |
| V | MALE | 75 | CORRELL | V | C | <NA> |
| V | MALE | 75 | DEAL | R V | ROB | <NA> |
| V | MALE | 49 | DEHART | V | L | JR |
| V | MALE | 90 | DREYER | V | DEAN | <NA> |
| V | MALE | 57 | GORDON | V | H | <NA> |
| V | MALE | 59 | HELTON | V JOHNNY | <NA> | <NA> |
| V | MALE | 76 | HICKS | V | L | <NA> |
| V | MALE | 81 | HOLLAND | V | L | <NA> |
| V | MALE | 0 | HOLLINSHED | V | E | JR |
| V | MALE | 60 | HONEYCUTT | V | J | <NA> |
| V | MALE | 60 | HOUSEHOLDER | V | R | <NA> |
| V | MALE | 105 | IDOL | V | F | <NA> |
| V | MALE | 84 | IRAGGI | V | J | <NA> |
| V | MALE | 30 | IYER | V V | <NA> | <NA> |
| V | MALE | 80 | JACKSON | V | L | <NA> |
| V | MALE | 25 | JEFFRIES | V'GER | S | <NA> |
| V | MALE | 65 | JONES | V | W | <NA> |
| V | MALE | 67 | KRASNIEWICZ | V | A | <NA> |
| V | MALE | 105 | KRITES | V | C | <NA> |
| V | MALE | 80 | KRYSTOFIAK | V | L | <NA> |
| V | MALE | 105 | LEWIS | V | M | <NA> |
| V | MALE | 60 | LIND | V WILLIAM | <NA> | JR |
| V | MALE | 87 | LOCKAMY | V | B | <NA> |
| V | MALE | 51 | LOMBARDI | V ALAN | <NA> | <NA> |
| V | MALE | 65 | MANGIPUDI | V RAO | <NA> | <NA> |
| V | MALE | 59 | MANN | R V | <NA> | <NA> |
| V | MALE | 54 | MARTIN | V | GRAY | JR |
| V | MALE | 71 | MATHENY | V | O | JR |
| V | MALE | 80 | MCKINNEY | V | A | <NA> |
| V | MALE | 53 | MODLIN | V | WAYNE | <NA> |
| V | MALE | 62 | NORMAN | V WAYNE | <NA> | <NA> |
| V | MALE | 33 | OAKLEY | V | BRADSHER | III |
| V | MALE | 70 | OATES | A V | <NA> | <NA> |
| V | MALE | 43 | OGLESBY | V | BOYCE | JR |
| V | MALE | 50 | PFAHL | V KEVIN | <NA> | <NA> |
| V | MALE | 60 | PIERANNUNZI | V PAUL | <NA> | <NA> |
| V | MALE | 58 | PLAYER | V | STEPHEN | <NA> |
| V | MALE | 75 | POWELL | V | A | JR |
| V | MALE | 70 | RASH | A V | <NA> | <NA> |
| V | MALE | 57 | REDMOND | V | PRESTON | JR |
| V | MALE | 60 | REVELS | V D | <NA> | <NA> |
| V | MALE | 89 | REYNOLDS | V | FRANK | <NA> |
| V | MALE | 85 | RUMLEY | V | CLIFTON | <NA> |
| V | MALE | 62 | SCALDARA | A V | <NA> | <NA> |
| V | MALE | 88 | SHIELDS | V | E | <NA> |
| V | MALE | 90 | SLADE | V | T | <NA> |
| V | MALE | 87 | TEMPLE | V | W | <NA> |
| V | MALE | 80 | WARD | V | STUART | JR |
| V | MALE | 57 | WHITE | A V | <NA> | JR |
| V | MALE | 70 | WHITSON | V | L | <NA> |
| V | MALE | 76 | WOOTEN | V | ALDENE | <NA> |
| V | MALE | 57 | WYATT | V | CHARLES | <NA> |
| VI | FEMALE | 82 | ANTHONY | VI | JOHNSON | <NA> |
| VI | FEMALE | 25 | DO | VI | THUY | <NA> |
| VI | FEMALE | 48 | GREENE | VI | HEGE | <NA> |
| VI | FEMALE | 28 | HUTCHINSON | VI | THI | <NA> |
| VI | FEMALE | 21 | LAI | VI | LE | <NA> |
| VI | FEMALE | 25 | NGUYEN | VI | THOAI | <NA> |
| VI | FEMALE | 20 | NGUYEN | VI | TUONG | <NA> |
| VI | FEMALE | 48 | TOWNSEND | VI | S | <NA> |
| VI | FEMALE | 28 | VO | VI | PHUONG | <NA> |
| VI | MALE | 58 | GALLOWAY | VI CKY | RONALD | <NA> |
| VI | MALE | 59 | THAI | VI | KY | <NA> |
| VI | MALE | 57 | TRAN | VI | TAN | <NA> |
I eyeballed the results and removed words which appeared to be mostly validly used.
Invalid words:
- As whole field: FATHER, III, IV, JR, MD, MR, MRS, SISTER, SR
- As first word: DR, MISS, MRS, REV, SISTER
- As last word: III, JR, MRS, NMN, SR
- As internal word: MRS
5.4.3 Middle name
# regular expression to match words
w_regexp <-
c(w_hons, w_gen, w_spec, w_test) %>% # all special words
unique() %>% # make it a set
dplyr::setdiff( # remove words that appear to mostly be validly used
c(
"BISHOP",
"BLIND",
"BR",
"BROTHER",
"DOCTOR",
"ELDER",
"FIRST",
"JR", # invalid & too many to display
"JUNIOR",
"MASTER",
"MISTER",
"MRS", # invalid & too many to display
"NMN", # invalid & too many to display
"PASTOR",
"SENIOR",
"SISTER",
"I",
"V",
"VI",
"VOTER"
)
) %>%
glue::glue(x = . , "\\b{x}\\b") %>% # must be words
glue::glue_collapse(sep = "|") # search for any
x <- d %>%
dplyr::mutate(
match =
midl_name %>%
stringr::str_to_upper() %>%
stringr::str_replace_all(pattern = "[^ A-Z]", replacement = " ") %>%
stringr::str_squish() %>%
stringr::str_extract(pattern = w_regexp)
) %>%
dplyr::filter(!is.na(match))
nrow(x)[1] 98x %>%
dplyr::arrange(match, sex, last_name, first_name) %>%
dplyr::select(match, sex, age, all_of(vars_name)) %>%
gt::gt() %>%
gt::opt_row_striping() %>%
gt::tab_style(style = cell_text(weight = "bold"), locations = cells_column_labels()) %>%
gt::fmt_missing(columns = everything(), missing_text = "<NA>")| match | sex | age | last_name | first_name | midl_name | name_sufx_cd |
|---|---|---|---|---|---|---|
| AKA | FEMALE | 57 | WISE | DIANA | AKA | <NA> |
| DR | FEMALE | 54 | CACCAMO | KATHLEEN | DR | <NA> |
| DR | FEMALE | 47 | DUNCAN | ROSALYN | DR | <NA> |
| DR | FEMALE | 27 | GEORGE | AMAY | DR | <NA> |
| DR | FEMALE | 67 | VANN | ELLEN | DR | <NA> |
| DR | MALE | 85 | ELESHA | WILLIAM | DR | <NA> |
| DR | MALE | 80 | ROBICSEK | FRANCIS | DR | <NA> |
| DR | MALE | 72 | ROPER | THOMAS | E DR | <NA> |
| DR | MALE | 77 | VETTER | JOHN | S DR | <NA> |
| II | MALE | 37 | BIRCHFIELD | HARRY | LYNN II | <NA> |
| II | MALE | 36 | DINGMAN | LEONARD | ALAN II | <NA> |
| II | MALE | 39 | FRADY | ROBERT | GLENN II | <NA> |
| II | MALE | 49 | GLOVER | CHARLES | WORTH II | <NA> |
| II | MALE | 35 | HAWKINS | ROGER | LARRY II | <NA> |
| II | MALE | 33 | HUNTER | ERNEST | II | <NA> |
| II | MALE | 48 | KELLY | DAVID | LEE II | <NA> |
| II | MALE | 45 | KERR | JAMES | II | <NA> |
| II | MALE | 62 | KUHNE | KURT | II | <NA> |
| II | MALE | 73 | ROGERS | SYLVESTER | II | SR |
| II | MALE | 60 | SHERWOOD | GEORGE | ROYALL II | <NA> |
| II | MALE | 34 | SOGLUIZZO | JOSEPH | JOHN II | <NA> |
| II | MALE | 91 | VAN GORDER | CHARLES | OSCAR II | <NA> |
| II | MALE | 31 | WALSTON | CHARLES | EDWARD II | <NA> |
| II | MALE | 30 | WATKINS | MONROE | II | <NA> |
| II | MALE | 35 | YOUNGMAN | THOMAS | ARDEN II | <NA> |
| III | MALE | 42 | BROWN | HARRY | III | <NA> |
| III | MALE | 56 | BROWN | MILES | III | <NA> |
| III | MALE | 23 | COOPER | DALTON | III | <NA> |
| III | MALE | 25 | DAILEY | LANGRA | III | <NA> |
| III | MALE | 32 | FUNDERBURK | TRAVIS | III | <NA> |
| III | MALE | 63 | GADISON | NATHANIEL | III | <NA> |
| III | MALE | 32 | GAY | ROBERT | HENRY, III. | <NA> |
| III | MALE | 53 | GEE | LAWRENCE | III | <NA> |
| III | MALE | 37 | HARPER | GUS | III | <NA> |
| III | MALE | 52 | HOLT | ISAAC | III | <NA> |
| III | MALE | 39 | HUMPHREY | ROLAND | M III | <NA> |
| III | MALE | 32 | JOHNSON | SHADE | III | <NA> |
| III | MALE | 30 | JOYNER | DOUGLAS | III | <NA> |
| III | MALE | 31 | LYNCH | ABRAHAM | III | <NA> |
| III | MALE | 46 | MCGILVERY | ROBERT | III | <NA> |
| III | MALE | 41 | MCILWAIN | FERRY | III | <NA> |
| III | MALE | 40 | PHILLIPS | ALEXANDER ROW | III | <NA> |
| III | MALE | 38 | PRICE | PAUL | III | III |
| III | MALE | 34 | STEELE | HARVEY | III | <NA> |
| III | MALE | 21 | TERRY | GEORGE | III | <NA> |
| III | MALE | 45 | THOMAS | PAUL | III | <NA> |
| IV | MALE | 26 | BAKER | LOUIS | IV | <NA> |
| IV | MALE | 46 | CROSS | EUGENE | IV | <NA> |
| IV | MALE | 33 | ESPOSITO | VINCENT | JOHN IV | <NA> |
| IV | MALE | 40 | GUNNOE | ROBERT | FELIX IV | <NA> |
| IV | MALE | 30 | HORNEY | HARRISON | MARTIN IV | <NA> |
| IV | MALE | 27 | HUMBERT | JOHN | LAWRENCE IV | <NA> |
| MD | FEMALE | 22 | BRONSON | JENNIFER | MD | <NA> |
| MD | MALE | 87 | MCGIMSEY | JAMES | F JR MD | <NA> |
| MISS | FEMALE | 105 | BOLES | FAUSTINE | MISS | <NA> |
| MISS | FEMALE | 90 | BREEZE | ALMA | EARL MISS | <NA> |
| MISS | FEMALE | 105 | DAVIS | JULIA | MISS | <NA> |
| MISS | FEMALE | 105 | GARBER | CORNELIA | MISS | <NA> |
| MISS | FEMALE | 77 | HAM | MABLE | MISS | <NA> |
| MISS | FEMALE | 105 | MCKOY | CAROL | MISS | <NA> |
| MISS | FEMALE | 105 | MORRISON | LULA | MISS | <NA> |
| MISS | FEMALE | 105 | MOSER | ROSE | MISS | <NA> |
| MISS | FEMALE | 105 | PHILSON | CHERYL | MISS | <NA> |
| MR | MALE | 47 | ATKINS | DAVID | GLEN MR | <NA> |
| MS | FEMALE | 105 | LIVENGOOD | THURMOND | MS | <NA> |
| NN | FEMALE | 30 | STINTZI | MANDI | LY NN | <NA> |
| NN | MALE | 33 | CRISSMAN | JASON | LY NN | <NA> |
| NN | MALE | 48 | GREENE | LESTER | D(NN) | <NA> |
| NN | MALE | 51 | LUKER | DANIEL | B(NN) | <NA> |
| REV | MALE | 0 | JOHNSON | ROBERT | REV | <NA> |
| REV | MALE | 68 | WORKMAN | NATHANIEL | REV | <NA> |
| SR | MALE | 54 | ABBAS | MOHAMED | SR | <NA> |
| SR | MALE | 35 | ANSTEAD | LENDELL | SR | <NA> |
| SR | MALE | 78 | ANTHONY | EVERETT | SR | <NA> |
| SR | MALE | 59 | ARMSTON | MILTON | SR | <NA> |
| SR | MALE | 71 | ARRINGTON | LEROY | SR | <NA> |
| SR | MALE | 62 | BATTLE | NATHANIEL | SR | <NA> |
| SR | MALE | 64 | BERRY | RALPH | SR | <NA> |
| SR | MALE | 79 | BROWN | NELSON | SR | <NA> |
| SR | MALE | 93 | CARTER | FOREST | SR | <NA> |
| SR | MALE | 43 | CLARK | JEFFERY | SR | <NA> |
| SR | MALE | 75 | DEGRAFFENRIED | EDWARD | (NMN)SR | <NA> |
| SR | MALE | 58 | EUBANKS | ALBERT | SR | <NA> |
| SR | MALE | 74 | HARRIS | MARION | SR | <NA> |
| SR | MALE | 58 | JOHNSON | FRED | ALAN SR | <NA> |
| SR | MALE | 89 | JONES | WALTER | SR | <NA> |
| SR | MALE | 44 | LANE | LORENZA | SR | <NA> |
| SR | MALE | 59 | LUPTON | DENNIS | WAYNE SR | <NA> |
| SR | MALE | 69 | LYNCH | LOUIS | SR | <NA> |
| SR | MALE | 54 | MILLER | CLARENCE | SR | <NA> |
| SR | MALE | 65 | OSBORNE | JOHN | SR | <NA> |
| SR | MALE | 48 | PERAGINE | PAUL | SR | <NA> |
| SR | MALE | 54 | SELLARS | LARRY | SR | <NA> |
| SR | MALE | 86 | STRICKLAND | TIMOTHY | SR | <NA> |
| SR | MALE | 82 | WHITAKER | WILLIAM | SR | <NA> |
| SR | MALE | 81 | WHITNEY | WILLIAM | PRESTON SR | <NA> |
| SR | MALE | 79 | WIGGINS | MINOR | SR | <NA> |
| SR | MALE | 38 | WILLIAMS | ERVIN | W., SR., | <NA> |
I eyeballed the results and removed words which appeared to be mostly validly used.
Invalid words:
- As whole field: AKA, DR, II, III, IV, JR, MD, MISS, MRS, MS, NMN, REV, SR
- As first word: JR, MRS
- As last word: DR, II, III, IV, JR, MD, MISS, MR, MRS, NMN, NN, SR
- As internal word: JR
Timing
Computation time (excl. render): 556.936 sec elapsed
sessionInfo()R version 4.1.0 (2021-05-18)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.10
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=en_AU.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_AU.UTF-8 LC_COLLATE=en_AU.UTF-8
[5] LC_MONETARY=en_AU.UTF-8 LC_MESSAGES=en_AU.UTF-8
[7] LC_PAPER=en_AU.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_AU.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices datasets utils methods base
other attached packages:
[1] glue_1.4.2 tidyr_1.1.3 skimr_2.1.3 ggplot2_3.3.3
[5] forcats_0.5.1 lubridate_1.7.10 vroom_1.4.0 stringr_1.4.0
[9] gt_0.3.0 dplyr_1.0.6 fs_1.5.0 here_1.0.1
[13] tictoc_1.0.1 targets_0.4.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.6 ps_1.6.0 rprojroot_2.0.2 digest_0.6.27
[5] utf8_1.2.1 R6_2.5.0 repr_1.1.3 backports_1.2.1
[9] evaluate_0.14 highr_0.9 pillar_1.6.1 rlang_0.4.11
[13] rstudioapi_0.13 data.table_1.14.0 whisker_0.4 callr_3.7.0
[17] jquerylib_0.1.4 checkmate_2.0.0 rmarkdown_2.8 labeling_0.4.2
[21] igraph_1.2.6 bit_4.0.4 munsell_0.5.0 compiler_4.1.0
[25] httpuv_1.6.1 xfun_0.23 pkgconfig_2.0.3 base64enc_0.1-3
[29] htmltools_0.5.1.1 tidyselect_1.1.1 tibble_3.1.2 bookdown_0.22
[33] workflowr_1.6.2 codetools_0.2-18 fansi_0.4.2 crayon_1.4.1
[37] withr_2.4.2 later_1.2.0 grid_4.1.0 jsonlite_1.7.2
[41] gtable_0.3.0 lifecycle_1.0.0 git2r_0.28.0 magrittr_2.0.1
[45] scales_1.1.1 cli_2.5.0 stringi_1.6.2 farver_2.1.0
[49] renv_0.13.2 promises_1.2.0.1 bslib_0.2.5 ellipsis_0.3.2
[53] generics_0.1.0 vctrs_0.3.8 tools_4.1.0 bit64_4.0.5
[57] purrr_0.3.4 processx_3.5.2 parallel_4.1.0 yaml_2.2.1
[61] colorspace_2.0-1 knitr_1.33 sass_0.4.0